这是最全面的 HBM2E 内存 IP 接口解决方案选型和实施指南。
最近,Rambus 产品管理高级总监 Frank Ferro 和 Joseph Rodriguez 在我们的线上设计峰会中,主持了一场网络研讨会,并在会间讨论了 HBM2 和 HBM2E 内存技术。
在开发高速 AI 产品时,我们需要做出很多决定,而 HBM 目前已成为其首选内存。接下来我们将详细讨论 HBM2E 内存的选型标准和实施细节。
让我们开始吧!
幻灯片分享: 来自 Rambus 的 HBM2E 实施与选型终极指南
HBM2E 网络研讨会听录:
为应对指数级数据增长而产生的更高带宽需求
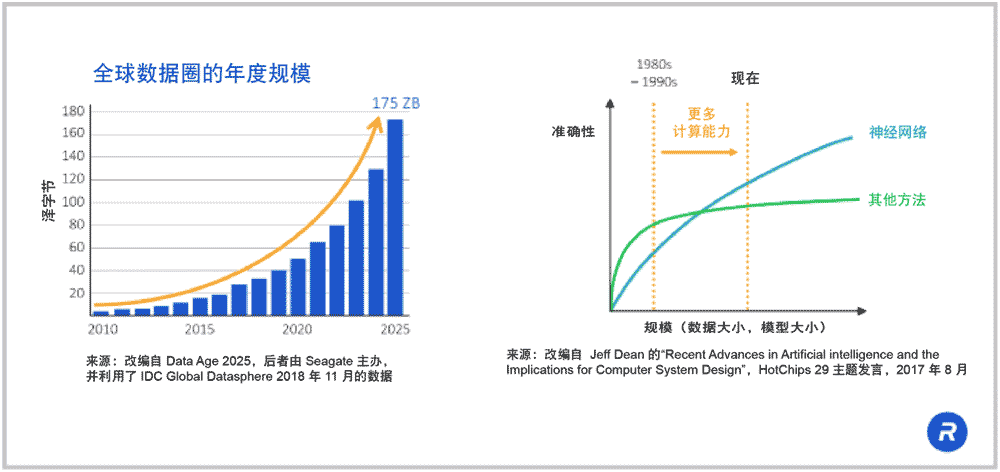 我们现今在半导体行业所做的一切均由数据的指数级增长所驱动。不断增长的数据需求给我们的所有系统带来了压力。它不仅对我们现有的计算机架构形成压力,也切实地驱动着技术创新,以进行不同的尝试。其中, 神经网络的确成为了 AI 计算领域的主流,并已存在了一段时间。然而,直到最近,计算能力才跟上了发展的步伐,神经网络才真正地发挥出其重要作用。
我们现今在半导体行业所做的一切均由数据的指数级增长所驱动。不断增长的数据需求给我们的所有系统带来了压力。它不仅对我们现有的计算机架构形成压力,也切实地驱动着技术创新,以进行不同的尝试。其中, 神经网络的确成为了 AI 计算领域的主流,并已存在了一段时间。然而,直到最近,计算能力才跟上了发展的步伐,神经网络才真正地发挥出其重要作用。
如今,算力已经赶上来了。可以看到,我们已具备足够的算力,而内存带宽却成为了当前系统瓶颈。我们拥有很多处理器,但却无法满足这些处理器的需求。目前采取的做法是使用 CPU 和 GPU 技术,不过,为了进一步提升神经网络的效率,定制处理器正在开发当中。这种处理器与 CPU 和 GPU 一样有效。此外,要使用那些定制处理器,您需要拥有 非常高的内存带宽 而正如我刚才所说,HBM 正在成为理想的内存。
让我们来看一些 HBM 特点。
HBM2E 与 GDDR6:AI应用所需的两种重要内存
 对于AI/ML应用您由两种内存选择,即 HBM 和 GDDR6。这两种技术都是为图形处理市场所开发的。
对于AI/ML应用您由两种内存选择,即 HBM 和 GDDR6。这两种技术都是为图形处理市场所开发的。
HBM2,也就是现在的 HBM2E,它的开发是为了与当前的 DDR DRAM 技术配合,以提供最大带宽。.
通过查看上方HBM2E 图片,您会发现大量内存堆栈。
因此当下的HBM技术,是采用现有 DRAM 技术,并将其以 3D 堆栈方式进行配置。另一种元素是硅中介层,用于将处理器与内存堆栈互连。
每个 HBM2E 设备均通过一个 1024 位宽的数据接口连接。加上控制平面层,走线的数量增加到大约 1700 条。远远超过标准 PCB 所能支持的限度。通过使用硅中介层,便能够打印出精细的数据走线,实现2.5D 架构。
HBM2E 利用现有的 DRAM 技术,结合 3D 和 2.5D 制造技术,可提供极高带宽。
另一种流行的内存是 GDDR6, 同样,这种内存也是为图形处理市场开发的。由于 GDDR6 的高性能,具备高达每秒 16 或 18 吉比特 (Gbps) 运行速度,对于某些 AI 应用来说,它也是一种非常具吸引力的解决方案。
您还可以查看一些目标应用。总之,HBM 一直是 AI 训练应用的优良解决方案,因为 AI 训练属于数据密集型,需要尽可能大的带宽。

要知道,人们训练这些 AI 算法时,可能要数天甚至数周才能获得正确的训练结果,因此,这个过程需要结合大量带宽和处理能力。
这些模型经过训练后,就会出现另一个过程,即 AI 推理。AI 推理所需的算力要少得多。它需要的是更高的成本效率,因为我们会将其广泛部署于各个端点,这些端点不仅是实施 AI 的地方,也是 GDDR6 的介入之处。
继续阅读:
– HBM2 还是 GDDR6?
– HBM2 和 GDDR6 的高速公路车道
HBM2E 4G 公告
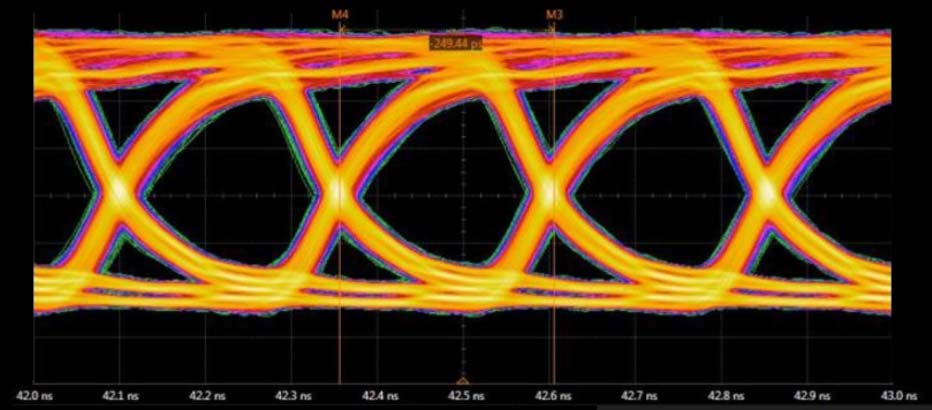
在我进行产品介绍前,Rambus 刚刚 宣布了我们在 HBM 领域获得的最新成就。
我们使用 HBM2E 实现了每秒 4Gbps 的性能,这是很重大的成果,因为目前 HBM2E 产品标准是 3.2Gbps,部分 DRAM 制造商可以提供 3.6Gbps的性能。
我们与 DRAM 制造商、ASIC 合作伙伴和制造合作伙伴合作开发了这款高速测试芯片。您可以看到,我们已经实现了非常清晰的眼图(见上图)。这个结果得益于我们做了大量仿真工作,取得了正确的中介层设计。
有了 HBM,您就可以通过硅中介层传递成千上万的信号。就串扰和插入损耗方面,正确的设计尤为关键。
Rambus 公司以信号完整性闻名。4Gbps 的HBM2E性能实现,显示了我们有研发最高速的内存接口能力,并持续引领行业。
正如我刚才提到的,开发 AI 硬件的公司需要更高的带宽。那么,继续向前推进并实现 HBM最大带宽的这种能力是至关重要的。
选择正确的内存:数据对比(表格)
在这张表中,我们展示了不同内存的选型标准,同时我也在这张图中介绍了几种不同内存。从中,您可对所有适合AI应用的内存有一个大致了解。
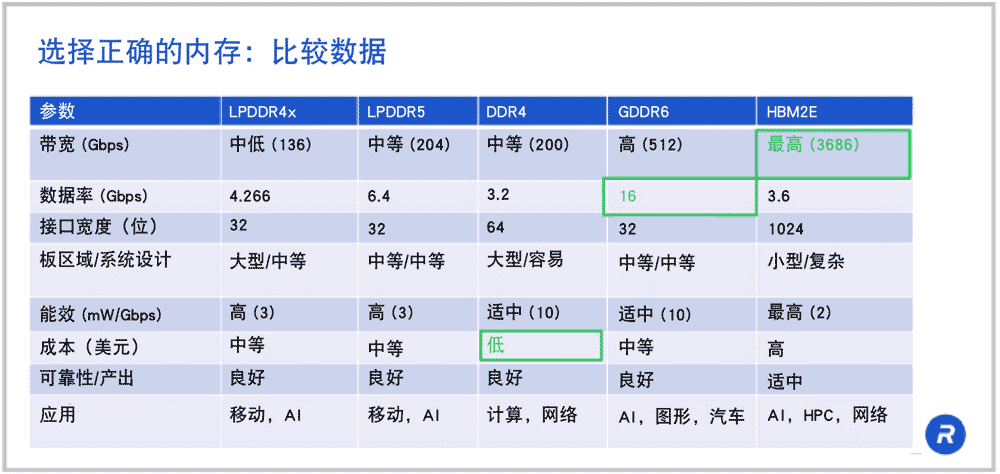
从左边开始,首先是 LPDDR。LPDDR 原先是为“LP”移动市场开发的,“LP”即低功耗。随着智能手机的设计愈加精密复杂,移动设备行业在带宽方面同样面临巨大压力。例如, LPDDR4从前的运行速度为 4.2Gbps。刚被引入时,它是运行速度最快的内存之一。
带宽是数据速率和接口宽度的乘积。LPDDR4 是 4.266Gbps 的数据速率乘以 32 位宽接口,等于 136.5Gbps 带宽。将这个数字除以 8,把比特转换为字节,您就能得出一个每秒 17GB(即 17GB/s)的带宽。通常带宽的单位是 GB/s。
继续阅读:
– AI 需要定制 DRAM 解决方案:第 1 部分
– AI/ML 和 HPC 适用的高性能内存:第 2 部分
LPDDR4 和 LPDDR5 适用于 AI 端点。从汽车应用到类似于 Alexa 等家居智能设备,均为端点。在这些的场景中,您并不需要其具备强大的处理能力,但却需要非常低的成本和功耗。
然而,当我们向网络边缘,甚至云端转移时,LPDDR 便无法提供足够的带宽,这时您就会需要 GDDR6 和 HBM 内存之类的解决方案。
DDR 是服务器和 PC 中所使用的一种传统主机内存。DDR4 的运行速度为 3.2Gbps,在 64 位宽的配置中,所提供的带宽能够与LPDDR5相竞争。但是,仍然无法满足新兴的 AI/ML 应用的带宽需求。
再说到 GDDR6,它的数据运行速率为 16Gbps,所提供的带宽是 LPDDR5 或 DDR4 的 2.5 倍。刚才已经展示过,我们能够将 GDDR6 的运行速度提升至 18Gbps。
如果 HBM2E 在 1024 位宽接口上以 3.6Gbps 的速度运行,那么就可以得到每秒 3.7Tb 的带宽,这是 LPDDR5 或 DDR4 带宽的 18 倍以上!所以何不一直使用 HBM2E 呢?可能是因为对于中介层的需求,让解决方案更加复杂、成本更高。所以,您需要在价格和性能之间进行权衡。
来自 Rambus 的 Steven Woo 解释了 GDDR6 – HBM2 的设计权衡 (SemiEngineering)
HBM2E 满足很多要求。您得到了最小的占用面积。您得到了非常优秀的功率效率,因为目前已经是 3.6Gb 这样一个“相对低”的运行速度了。这样运行确实很宽很慢,但面对 3D 和 2.5D 架构时,设计更加复杂,制造商的成本也会更高。
如果您不需要 HBM2E 的带宽,而想要更传统一些的制造方式,只需考虑 PCB。选择 GDDR6,您就可以利用传统的批量制造流程,实现任何 2D 内存替代方案的最佳性能。
HBM2E 解决方案摘要
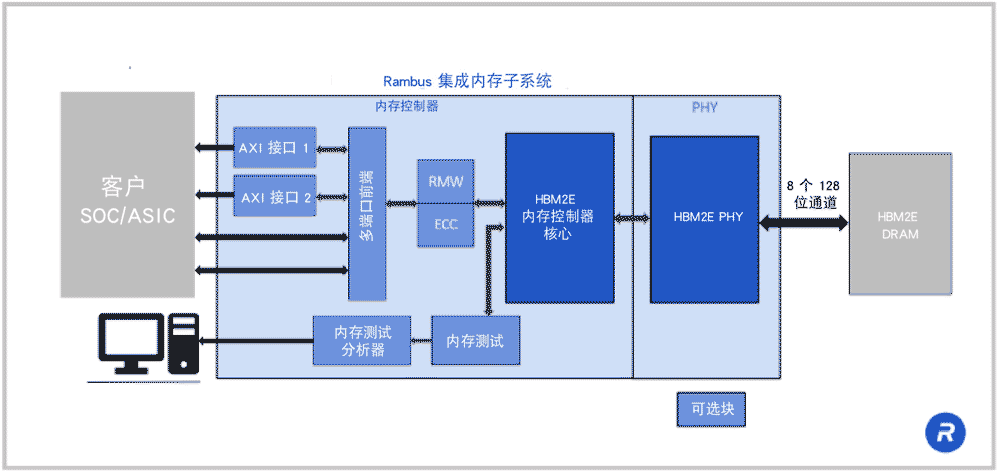
此处您可以查看Rambus HBM2E 解决方案。在中间的浅蓝色区域,您可以看到我们的 HBM2E 内存 PHY 和控制器。这是完整的 HBM2E 内存子系统。 PHY 是作为硬核化的、完整的和时序闭合的宏来提供的,我们会使用HBM2E 内存控制器对其进行验证对其进行验证。
将 PHY 和内存控制器结合,可以大大简化工程设计工作,因为您所开发的是内存子系统。Rambus 处理了大量内存方面的繁重工作,并且我们的内存控制器具备适用于系统中 SoC 或 ASIC 的主流接口。与 Rambus 合作的一大优势是,我们拥有丰富的生产经验。稍后将展示,我们长期以来经过大量投产的HBM设计。
强调一下,购买 IP 时,确定 IP 已经过生产测试是非常重要的。
我们想让您了解,这样的 IP 能够在首次生产时获得成功。Rambus 的另一个独特之处,是我们不仅提供 IP,还提供完整的系统设计支持。
我们可以提供中介层和封装的参考设计。这对开发 AI 硬件的公司来说,又是一项巨大的助益,因为我们已经带您完成了四分之三的进程了。当我们把设计交给您时,您得到的是中介层参考设计,我们还会提供封装设计建议,您也会得到完整的内存子系统。
Rambus 还有一个非常大的优势。
最后,我们会提供名为 Lab Station, 的工具,一种非常先进的工具,由 Rambus 的信号完整性专家历经 25 年研发而成,实现内存接口完整表征。
而且,它还能够配合点亮您的系统。例如,如果您的 ASIC 是第一次启动,当您给了 PHY 和控制器一个时钟信号后,Lab Station 将允许您查看 DRAM、物理层和 PHY 之间的接口,您甚至可以在 ASIC 处于调试中时,启动、运行或调试接口。
这是一个非常强大的解决方案。
当然,从功能角度,我们支持所有符合JEDEC 规格的,具有不同速率(最高4Gbps)的HBM2/2E 标准功能。同时我们也支持所有不同供应商的 HBM2/2E DRAM。我们支持通道修复等功能。有一种 IEEE 1500 测试支持,是标准的一部分。
中介层参考设计。
中介层参考设计
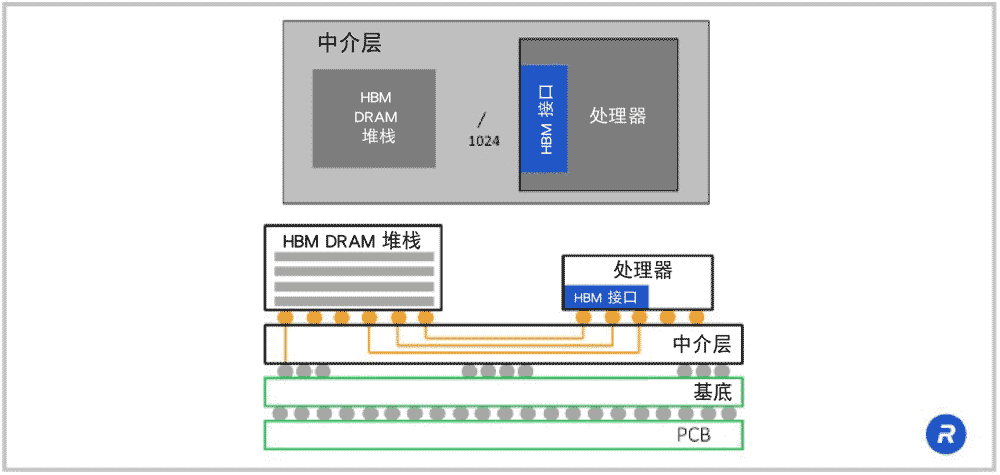
上文提到过的中介层参考设计,如您所见,我谈了很多有关处理器和 DRAM 堆栈之间的接口的内容。
上图为您展示了一个简化框图,图中是带 HBM 接口的处理器,而后是橙色信号走线,它们穿过硅中介层,到达 DRAM 堆栈。
如何设计这些穿过硅中介层的信号走线?
在设计硅中介层时,必须意识到您将面临许多HBM 的设计挑战。例如,创建这些信号走线需要多久?这些走线的间距是多少?金属的厚度是多少?有多少金属层?底层应放在哪里?
答案因实施类型而异。也因使用的工艺节点而异。Rambus将为所有主流制造商,以及您将设计的不同类型的系统,提供参考设计。 我们拥有大量的生产经验,通过与您协作,来深入了解您的设计。我们会提供通道模拟,以及有关如何实施中介层设计的建议和反馈。
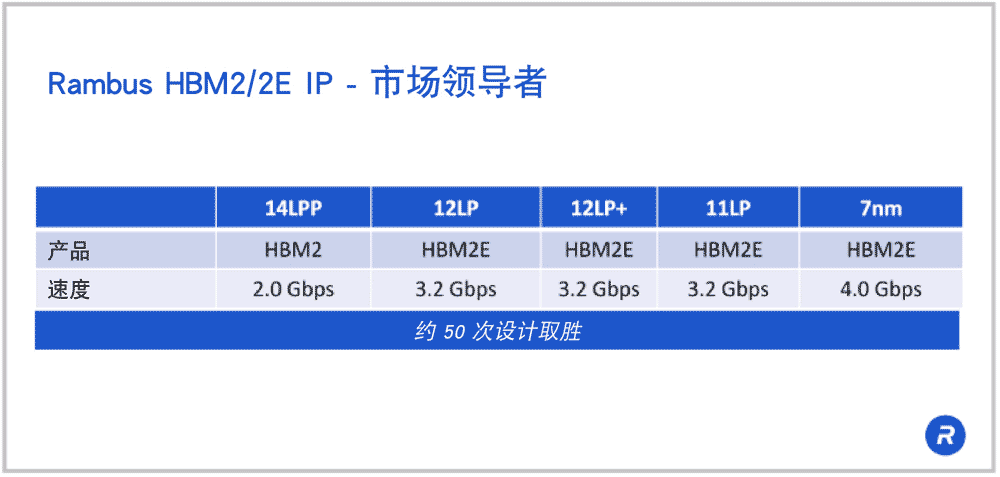
Rambus HBM2/2E IP 的市场领先地位
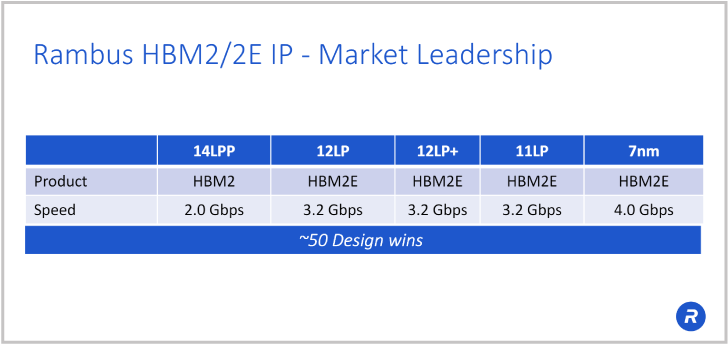 我们提供完整可配置的 HBM2E 内存解决方案,其中包括我们的控制器和关联附加内核。这个解决方案在超过50个客户设计和一些测试芯片中广泛部署。我们能够为您的设计和架构提供帮助,回答您在系统中介层设计方面的任何问题。
我们提供完整可配置的 HBM2E 内存解决方案,其中包括我们的控制器和关联附加内核。这个解决方案在超过50个客户设计和一些测试芯片中广泛部署。我们能够为您的设计和架构提供帮助,回答您在系统中介层设计方面的任何问题。
HBM2/2E 内存接口解决方案:控制器内核
HBM2E 可以提供无与伦比的带宽,这得益于高达 4.0Gbps 的数据速率。AI/ML 也需要高内存容量,而 HBM2E 可以支持 12 高 DRAM 堆栈,并且能够在每个通道处理 24Gb 密度。

为了充分利用内存容量和带宽,可根据您应用确切的内存模式和流量大小, 对Rambus 内存控制器进行配置。例如,如果您需要单次的,仅为有限的 32 字节内存访问,我们可以相应地为此配置一个双内存控制器解决方案。我们可以根据您的要求调整控制器,通过提供更低门数,或更高效率,或获得更精细内存模块颗粒度等方式满足您的算力需求。
我们还为实现“RAS” (即可靠性、可用性及服务能力)增加许多不错的功能,如 ECC,以及最近新加的 ECC 清洗。
我们支持完整的功能测试,并提供完全集成的控制器以及经过验证的PHY。
我们也能够帮助您进行测试。
除基于硬件的验证外,我们还拥有基于工厂的且使用 UVM 的大规模验证环境。
我们使用 Samsung 和 SK Hynix 内存模型,以及 Avery 的设计系统、内存模型和显示器。
可以保证的是,您无需在调试 PHY 和控制器交互方面花费时间。我们会向您提供PHY和控制器集成的高质量可重复使用的 IP。 我们的控制器解决方案非常成熟,具有100%一次到位成功交付性能的记录。
为什么选择 Rambus HBM2/2E?
总体而言,如果您接下来的设计需要 HBM2/2E 内存,那么很明确,Rambus 将会是您的选择。
- 我们完成超过 50 个以上的客户设计,是目前的市场领导者。我们也是性能领域的领导者,以及唯一能够实现 4Gbps 的 IP 供应商。
- 我们提供完全集成且经过硅验证的 PHY 和控制器解决方案。
- 我们的首次硅成功率为 100%。
- 我们提供中介层和封装参考设计,可减少您的设计工作和风险。
- 我们提供 Lab Station 开发环境,可加速首次启动
另外,我们在售前、售后和首次启动阶段,均会为您提供行业领先的专业技术支持。
下一步?
要了解有关 HBM2E 和所有接口 IP 解决方案的更多信息,请在此处联系我们,并申请与我们的销售专员会面。
相似主题:
– 关于 HBM 和 GDDR6 的所有信息
– HBM2 因半导体行业关注 HBM3 而获得升级
– eSilicon 推出 7 纳米组合 PHY(HBM2/HBM2E/低延迟)测试芯片
发表回复