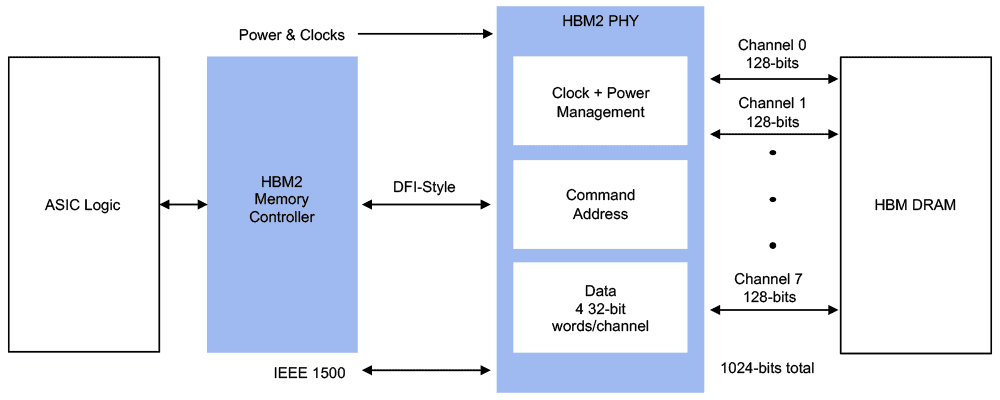
At Rambus, we create cutting-edge semiconductor and IP products, providing industry-leading chips and silicon IP to make data faster and safer.
At Rambus, we create cutting-edge semiconductor and IP products, providing industry-leading chips and silicon IP to make data faster and safer.
 联系方式
联系方式 产品简介
产品简介