専門家に聞く: Dr. Steven Woo
AIは急速に進化しています。昨年、生成AIアプリケーションの急速な発展により、私たちは今やAI 2.0の時代へと突入しました。この時代は、大規模な言語モデルによってAIが何百万もの消費者や企業に利用され、創造性とイノベーションの無限の可能性を提供するという特徴があります。 先日、Rambus Labsのフェローであり著名な発明家でもあるSteven Woo博士にインタビューを行い、AI 2.0と、今後のAIを形作る主要なテクノロジーについて詳しく聞きました。
AI 2.0とは?
AIは私たちの日常生活に浸透してきています。ホームアシスタントに天気を尋ねたり、検索エンジンを使ったり、今日観るべき映画を勧められたりしたことがありませんか?それらはすべてAI 1.0がひっそりと機能していると言えるでしょう。これらのAI対応アプリケーションは、システムにインテリジェンスを組み込むという点で目覚ましい進歩を遂げていますが、入出力の選択肢は限られています。例えば、音声を使って音声を出力したり、テキストを使ってテキストを出力したりといったことしかできません。これらのシステムは、データを分析し予測を行うだけで、その過程で何か新しいものを生み出すことはありません。

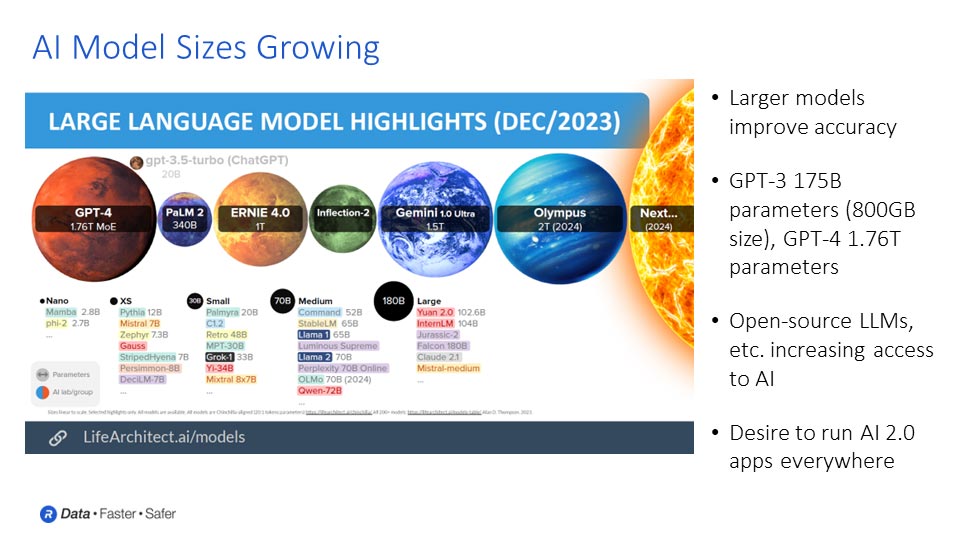
ChatGPTのようなアプリケーションの急速な発展により、AIはデータから何か新しいものを生み出すシステムを備えた次の段階、つまりAI 2.0へと確実に移行しました。この進化は、大規模言語モデル(LLM)によって可能になる生成AI機能を特徴とする新しい時代の到来を告げています。これらのLLMは、テキストやその他のメディアなど、複雑な入力を解釈し、従来のテキストベースの応答から、コード、画像、動画、さらには3Dモデルといったより高度な形式まで、幅広い出力を生成することができます。このマルチモダリティ、つまり入力と出力の幅広い組み合わせは、創造性とイノベーションの無限の可能性を切り開きます。

AI2.0の大規模言語モデルはどのように学習されるのでしょうか?
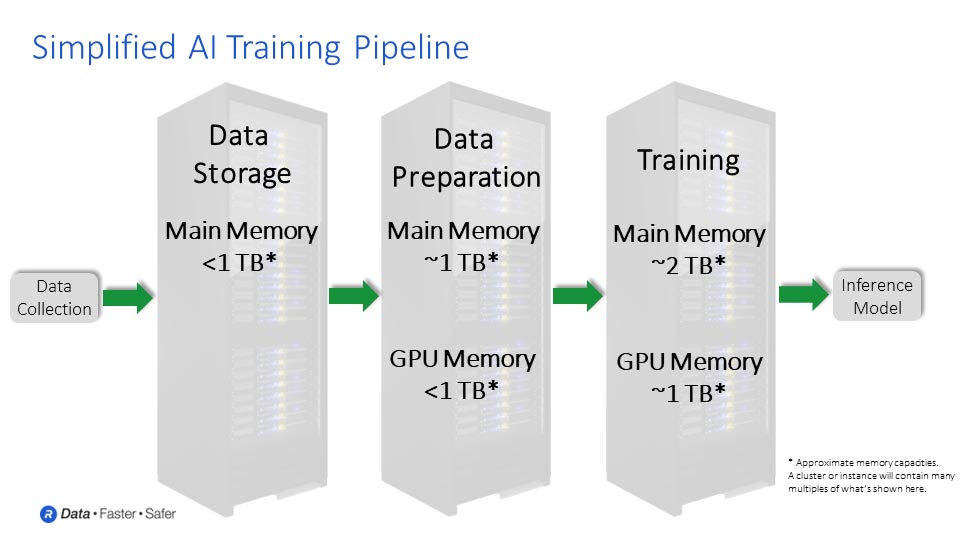
LLMの学習は、モデルの学習に使用するデータの収集から始まる、複雑で複数のステップからなるプロセスです。最先端のLLMは、数千億、あるいは数千兆ものサンプルに及ぶデータセットを使用します。収集されたデータは、学習の準備として分析、処理、そしてクリーンアップまたは正規化を行う必要があります。
この特定の目的や分析のために選択、整理されたデータセットを使用し、次の段階に進むことができます。この段階では、選択したアルゴリズムを用いてデータセットの学習を開始できます。LLMの学習を例に挙げると、モデルに単語のシーケンスを与えたときに、そのシーケンスで次に出てくる単語を正確に予測できるように学習します。このようにして、モデルは言語を生成する方法を学習し始めます。
モデルは、いくつかの単語をつなぎ合わせ、提示されたプロンプトや質問に基づいて、論理的に意味を成す次の単語を予測することを学習します。この反復学習では、ニューラルネットワークに層を追加したり、モデルの各層での出力への反応方法を変更したりするなど、通常、いくつかの調整が必要になります。
予期せぬ出力が得られたり、当初期待していたほど精度が高くなかったりする可能性があります。その場合、追加の改良と最適化が必要になります。期待される精度を維持し、エンドユーザーからの問い合わせに十分に答えられるようにするために、モデルと一部のパラメータを微調整する必要があったりします。
この学習プロセスの出力はAI推論モデルです。推論こそが真の面白さの始まりです。学習プロセスによって生成されたモデルは、何百万人ものユーザーに提供され、学習済みのモデルを超えた新しいコンテンツの作成に活用されるようになります。
AIの普及は推論側で起こっているのでしょうか、それとも学習側で起こっているのでしょうか、それとも両方でしょうか?AIの民主化にはどのような意味があるのでしょうか?
AIの普及は推論の分野で既に始まっています。ChatGPTのような生成AIアプリケーションは、AI推論を誰もが利用できるようにするための大きな変化をもたらしました。
同時に、オープンソースのAIモデルやフレームワークのトレンドも拡大しています。これにより、AI推論の進歩に貢献できる開発者や専門家の領域が拡大するだけでなく、最終的には学習面でもAIの普及が進むでしょう。
ハードウェア面から見ると、推論に一般的に使用されるハードウェアは、学習に必要なほど先進的ではありません。しかし、時間の経過とともに、半導体業界はこれまで通り、より低コストでより高い処理能力を提供していくでしょう。未来の半導体は、現在ではローカルで実行するには困難すぎると考えられているタスクを、パソコン、ノートパソコン、さらには携帯電話でも容易に実行できるようになるでしょう。
時間の経過とともに、私たちが自分のマシンでローカルに実行できる推論の種類は向上していきます。これは、業界が提供するより低コストで高性能な半導体によって部分的に推進されるでしょう。そして、これは学習にも波及し、人々は携帯電話やノートパソコンを使ってローカルに学習を行うようになるでしょう。これもまた、半導体業界がチップの性能向上とコスト削減を継続していくという事によって実現されていきます。
全体的に、Nvidia、AMD、Intel などの企業が提供するチップやプロセッサは、今後もさらに高性能化し、業界は AI の普及をサポートするより優れた機能を提供できるようになります。
今後の AI 2.0 にとって重要なチップ技術にはどのようなものがあるでしょうか?
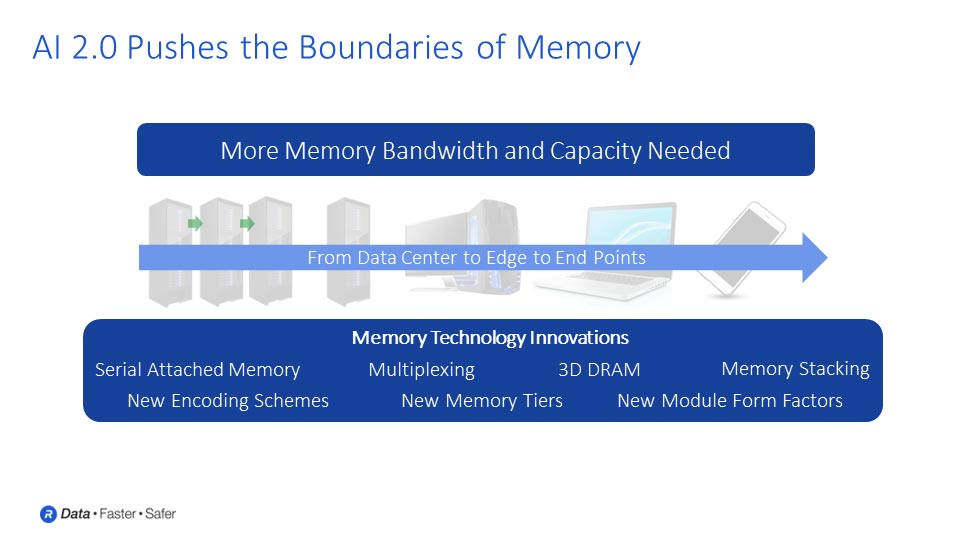
将来の大きな課題は、より高いパフォーマンスと優れた電力効率を提供することです。AIチップとプロセッサコアはますます高速化し、より高性能になり、1秒あたりの計算処理能力も向上します。これらのコアにデータを供給し、高効率で動作し続けるための技術が、重要な鍵となります。膨大な量のデータをプロセッサ間でやり取りできるようにするメモリとの相互接続技術が、ここで鍵となります。言うまでもなく、これらのデータはすべて非常に貴重なため、AIデータとモデルを悪意のある攻撃者から保護することがますます重要になります。
プロセッサの動作速度が速まると、プロセッサ間だけでなく、プロセッサからメモリへのデータ転送も高速化する必要があります。克服すべき課題の一つに、データ移動に伴う電力問題があります。データ移動に必要な距離が長く、かつ高速に転送したい場合、消費電力は増大します。この場合、メモリをプロセッサやその他のチップに直接積層することで、移動距離を短縮し、消費電力を削減することを検討するでしょう。
テクノロジーが高速データレートで信号伝送を開始すると、新たな課題も生じます。プロセッサとメモリ間、そしてプロセッサとプロセッサ間のチャネルやリンクにおいて、高データレートで信頼性の高いデータ伝送を行うことはますます困難になります。こうした状況において、新たな技術が登場する可能性が高いでしょう。マルチPAM信号伝送は、データレートの継続的なスケーリングをサポートするために採用される可能性が高い技術の一例です。
メモリの場合、データ転送速度の向上だけでなく、チップあたりのビット数も増加します。チップにより多くのビットを対応するためにセルが縮小されるにつれて、管理すべき他の影響も出てきます。これにはOn-Die Errorも含まれます。On-Die Error Correctionは、現在よりもさらに普及していくでしょう。また、RowHammerやRowPressといった、特定のセルへのアクセスが隣接するセルに悪影響を及ぼす可能性のある影響にも対処する必要があります。
考慮すべき動向もあります。AI 2.0時代は、量子コンピューティングと同時に到来しつつあり、量子コンピュータは、AI 2.0の基盤となるデータ、アルゴリズム、モデル、そして現代社会を支えるデータやトランザクションの保護において、新たな課題をもたらします。量子耐性の高い暗号は、これらの貴重なAI資産と、消費者や企業の個人データを保護する上で極めて重要になります。
例えば、Rambus Labsは業界と同様に、これらの分野のいくつかを研究しています。私たちは現在業界が直面している課題を深く認識しており、多くの優秀な人材がこれらの課題解決に取り組んでいます。これは、メモリとインターコネクトが、AI 2.0の実現に向けて業界が今後必要とするパフォーマンスレベルを継続的に提供し続けるための鍵となるでしょう。

Leave a Reply