Improvements in DRAM interface throughput have rapidly outpaced comparable improvements in core speeds. Whereas data rates of DRAM interfaces have increased by over an order of magnitude over successive generations, the DRAM core frequency has remained relatively constant. Over time, core prefetch size has increased in order to keep pace with improvements in interface bandwidth. However, larger prefetch sizes increase access granularity—a measure of the amount of data being processed—and deliver more data than necessary, causing processing inefficiencies. Micro-threading is a unique DRAM core access architecture that improves transfer efficiency and effective use of DRAM architecture resources by reducing row and column access granularity. By providing independent addressability to each quadrant of the DRAM core, micro threading allows minimum transfer sizes to be four times smaller than typical DRAM devices, complementing the threaded memory workloads of modern graphics and multi-core processors. This unique architecture enables micro-threading to maintain the total data bandwidth of the device while reducing power consumption per transaction.
- Improves transfer efficiency for multi-core computing applications
- Doubles DRAM core data rate versus conventional techniques
- Maintains high sustained bandwidth while lowering power consumption
What is Micro-threading Technology?
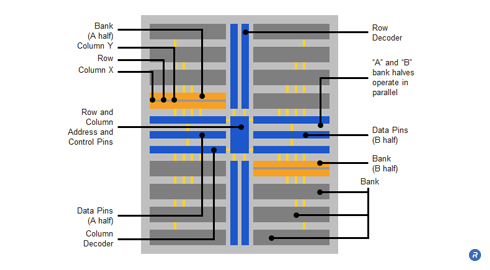
Access granularity is a function of the accessibility of data within a memory architecture. A typical DRAM is comprised of eight storage banks. Within such DRAMs, each bank is typically further subdivided into two half banks, “A” and “B”. For such a DRAM with 32 data pins, each A half bank is connected to 16 data pins and each B half bank is connected to 16 pins. The banks are in opposite quadrants of the physical die, and each quadrant has its own dedicated row and column circuitry – each bank half operating in parallel in response to the row and column commands.
A row command selects a single row in each bank half of the bank being addressed, thereby sensing and latching that row. Physical timing constraints impose a delay (i.e., tRR) before a row in another bank can be accessed. Column commands are similarly constrained (i.e., tCC). However, the row timing interval is typically twice the column timing interval; therefore two column commands can be issued during the mandatory delay required for a single row activation.
The column prefetch length, the amount of data delivered per transaction, is determined by the respective column and row timing delays and bit transfer rate, where:
Prefetch = timing delay/bit transfer rate
A core of a mainstream DRAM typically operates up to 200MHz, whereas a core of a high performance industry standard DRAM can typically operate up to 400MHz. Core frequencies exceeding 400MHz are difficult to achieve using modern industry standard DRAM technologies without sacrificing production yields or increasing costs. Therefore, a column prefetch of 16bit is required for such a high performance DRAM core to support external data rates exceeding 3200 MHz since the DRAM cores is organized with each half-bank operating under the same row or column operation
In addition:
Column granularity = (column prefetch) x (number of data pins per half bank) x (number of half banks per access)
Or:
For a 32-bit wide DRAM with 16 data pins per half bank:
Column granularity per access = 16 x 16 x 2 = 512 bits or 64 bytes.
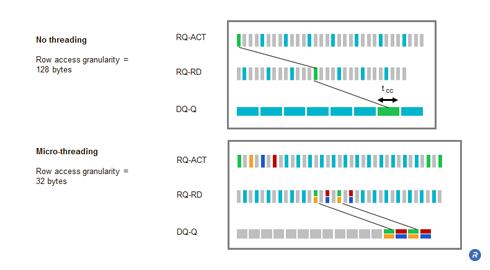
Moreover, during the row timing interval, in order to maintain peak bandwidth, at least two column operations must be performed. This is typically described as two column address strobes per row address strobe (two CAS per RAS). This results in a minimum row granularity of 128 bytes. This large access granularity translates into inefficient data and power utilization for applications such as 3D graphics.
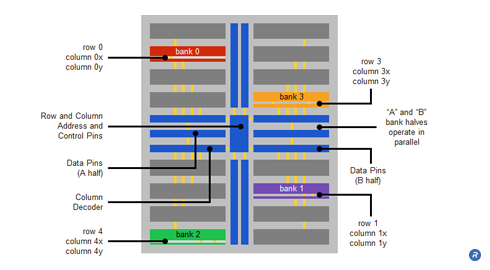
Using largely the same core resources as in the previous example, a sample micro-threaded DRAM core has 16 banks, each bank in the micro-threaded DRAM being equivalent to a half bank in the typical DRAM core. The even numbered banks connect to the A data pins and odd numbered banks connect to the B data pins (again with 16 pins in each case). However, unlike a typical core, each four-bank quadrant can operate independently, through the use of independent row and column circuitry for each quadrant. Moreover, interleaving, simultaneous access to more than one bank of memory, allows concurrent accesses to the lower quadrant on the same physical side of the core as the previous access.
Micro-threading enables four independent accesses to the DRAM core simultaneously. Although the same time interval as a typical core must still elapse before accessing a second row in a particular bank or bank quadrant, the three banks in the other quadrants remain separately accessible during the same period. Columns in rows in other quadrants can be concurrently accessed even though a column timing interval must pass before a second column is accessible in the previously activated row. The net effect of this quadrant independence and interleaving is that four rows (one in a bank of each quadrant) and eight columns (two in each row) are accessed during the row timing interval (compared to a single row and two columns with the typical DRAM technique).
Timings are similar to the typical DRAM core, but each column only sends data for half the column timing interval. The interleaved column sends data for the other half of the interval. Micro-threading reduces minimum transfer granularity size while maintaining a high-yielding and cost effective core frequency. By interleaving the column accesses from four different banks, a micro-threaded DRAM core (of a given column prefetch length and core frequency) can support data rate two times higher than that of a conventional DRAM core. Conversely, micro-threading of the column operation enables a DRAM core to cost-effectively sustain a specific data transfer and granularity while relaxing the column cycle time (tCC) by up to two times compared to those of a conventional DRAM core.
With micro-threading, column granularity is now:
Column prefetch/2 x 16 pins = 16/2 x 16 = 128 bits or 16 bytes (one quarter of the previous value).
The row granularity is 32 bytes (again one quarter of the previous value). Micro-threading’s finer granularity results in a performance boost in many applications. For example, in a graphics application with 8 byte micro-threaded column access granularity, computational and power efficiency increased from 29 percent to 67 percent after introducing the technique.
Who Benefits?
Micro threading enables twice the data rate from a DRAM core over conventional techniques, providing memory system designers high sustained bandwidth while lowering power consumption. In addition, micro threading benefits DRAM designers and manufacturers by providing an alternative approach to improve efficiency and reduce access granularity using largely the same DRAM core, reducing cost and risk.