Ask the Experts Interview with Dr. Steven Woo
AI is a rapidly evolving space. With the meteoric rise of generative AI applications in the past year, we are now firmly in the era of AI 2.0. This is characterized by large language models that place AI into the hands of millions of consumers and enterprises offering limitless possibilities for creativity and innovation.
We recently interviewed Dr. Steven Woo, fellow and distinguished inventor at Rambus Labs, to find out more about AI 2.0 and the key technologies that will shape it going forward.
Here is a summary of what we learned from our interview with Dr. Steven Woo.
What is AI 2.0?
AI is a huge part of our everyday lives. If you have asked your home assistant for the weather, used a search engine, or been recommended something to watch today, then that has all been AI 1.0 discretely at work. While these AI-enabled applications represent notable advancements in incorporating intelligence into systems, they do have a limited set of inputs and outputs. For example, you can use speech to output speech or text to output text. They are systems that analyze data and make predictions, without creating anything new in the process.

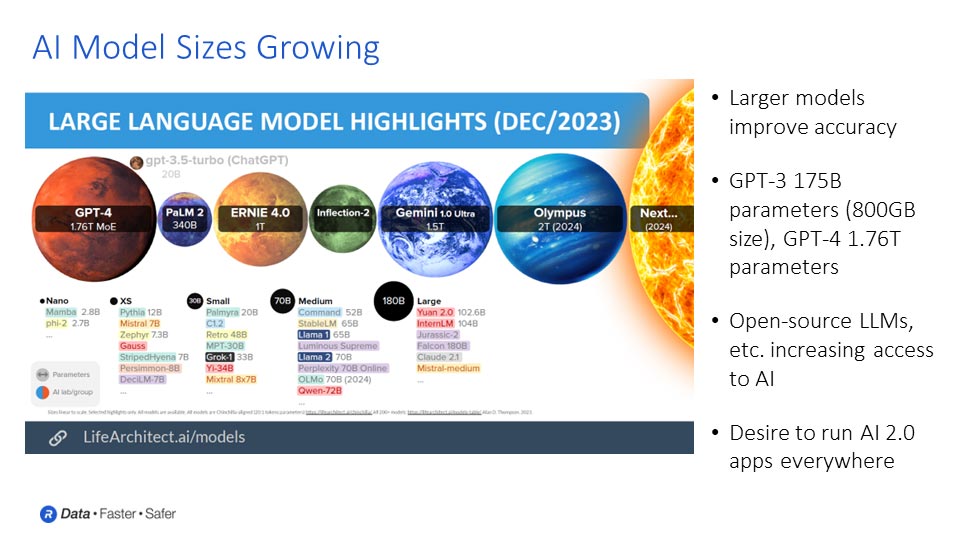
With the meteoric rise of applications like ChatGPT in the past year, we have now firmly transitioned to the next phase of AI where we have systems that can create something new from data; this is AI 2.0. This evolution marks a new era characterized by generative AI capabilities, made possible by large language models (LLMs). These LLMs can interpret complex inputs, be they text or other media, to deliver outputs ranging from traditional text-based responses to more advanced forms such as code, images, video, and even 3D models. This multi-modality, or breadth and combination of inputs and outputs, opens limitless possibilities for creativity and innovation.

How are the large language models behind AI 2.0 trained?
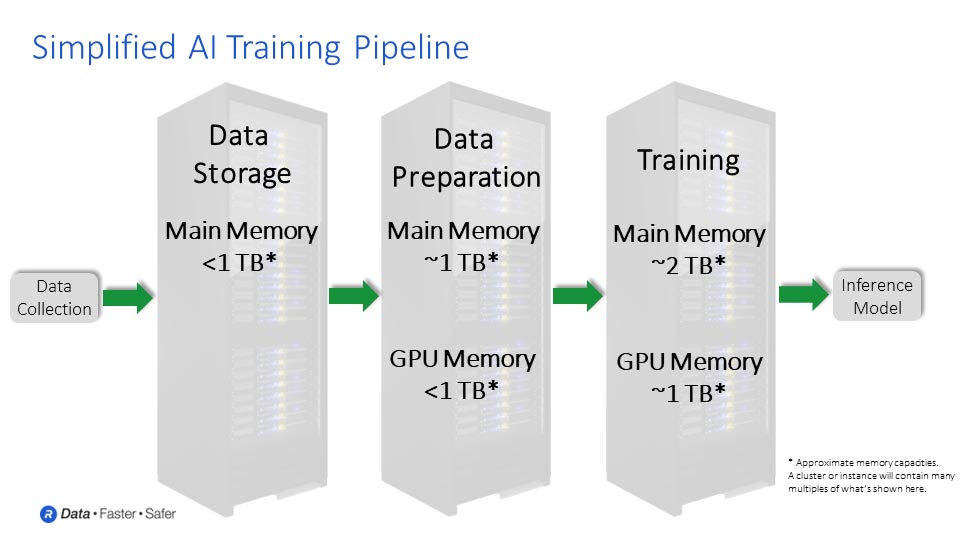
Training LLMs is a complex, multi-step process that begins first with collecting the data that you would like to train your model on. The state-of-the-art LLMs use data sets in the hundreds of billions or trillions of samples. Once that data is collected, it needs to be analyzed, processed, and cleaned up or normalized, to prepare it for training.
With this curated data set, the next stage can begin. At this stage, you can start to train the dataset using whatever algorithms chosen. As an example in training an LLM, you train the model so when it’s given a sequence of words, it can accurately predict the next word which should come out in that sequence. And that is how it starts to learn how to be able to generate language.
Based on a few words that it starts to string together; the model learns to predict what the next word is that makes logical sense based on the prompt or the question that the model has been asked. In this iteration, there are usually some adjustments to be made: adding layers to the neural network or changing the way outputs are reacted to at different layers of the model.
It is possible that there will be unexpected outputs, or the accuracy may not be as high as you had originally desired. In this case, some additional refining and optimizing are required. You may need to tweak the model and some of the parameters just to make sure that it maintains the level of accuracy expected and is fully capable of answering the queries that the end users are asking of it.
The output of this training process is an AI inference model. Inference is where the real fun begins. Now the model which is produced by the training process can be put in the hands of millions of users to create new content beyond what the model was trained on.
Is AI democratization happening on the inference side, or on the training side, or both? What are some of the implications of the democratization of AI?
AI democratization is already happening on the inference side. Generative AI applications like ChatGPT ushered in a sea of change that placed AI inference into the hands of everyone.
At the same time, there is also a growing trend for opensource AI models and frameworks. This expands the universe of developers and professionals that can contribute to the advancement of AI inference, but this will eventually lead to increased democratization of AI on the training side too.
Looking at the hardware side of things, the hardware typically used for inference is not as advanced as what you need for training. But over time, what will likely happen is the semiconductor industry will do what it always does, which is provide more horsepower at lower cost. The semiconductors of the future will be able to take on today’s tasks, which are considered too difficult to do locally, and make them easy to do on personal computers, laptops, and even cell phones.
Over time, the types of inference we can do locally on our own machines will become better, and that will be driven in part by the lower-cost, and more powerful semiconductors the industry will provide. And this will trickle into the training side too. People will start to do training locally on their cell phones or laptops. That, again, will all be provided by the fact that the semiconductor industry is going to continue to advance the capabilities of chips and continue to drive the cost down as well.
Overall, the chips and processors that we see from companies like Nvidia, AMD, and Intel, are going to continue to become more capable, and allow the industry to offer much better capabilities in support of the democratization of AI.
What are going to be some of the key chip technologies for AI 2.0 moving forward?
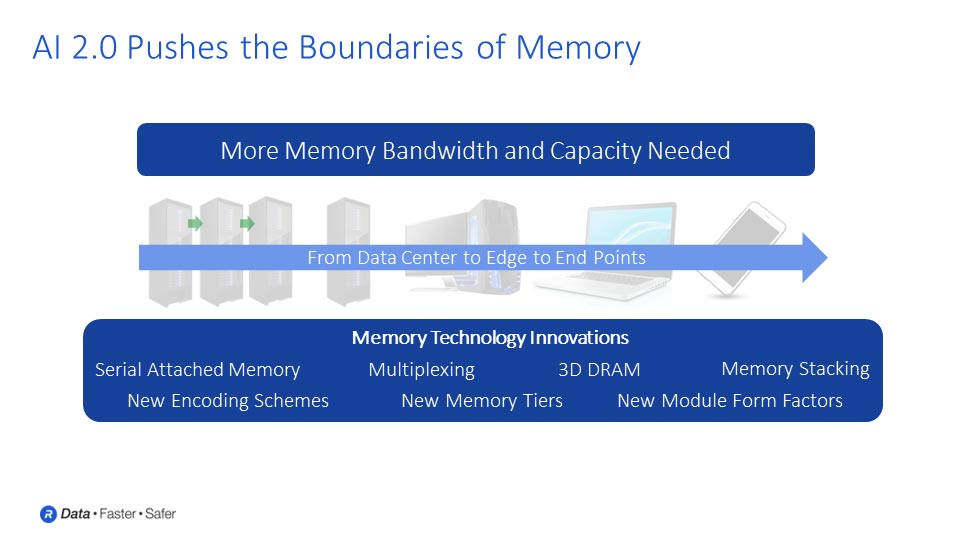
The big challenge in the future will be to provide more performance and better power efficiency. AI chips and processor cores are going to become faster. They will become more capable and be able to do more calculations per second. Some of the critical technologies are going to be the things that can supply data to those cores and keep them running at high efficiency. Memory and interconnect technologies will be key here as they are what enable vast amounts of data to move in and out of these processors. All this data is, of course, extremely valuable, so securing AI data and models against bad actors will become increasingly important.
If processors are going to run faster, then we are going to have to move data faster as well, both between processors and from processors to memory. Some challenges that must be overcome include the power associated with data movement. The longer the distance that you need to move the data, and the faster you want to move that data, the more power that you dissipate. What might happen, in this case, is that the industry will look at stacking memory directly onto processors and other chips to reduce the distance and save power.
There will be other challenges as technologies start to signal at faster data rates. It becomes harder to do reliable data transmission at higher data rates, on the channels and links between processors and memory, and between processors and other processors. This is where new techniques are likely to show up. Multi-PAM signaling will be one example of a technique that is likely to be adopted to support continued scaling of data rates.
In the case of memory, not only will there be movement of data at higher data rates, but there will be more bits per chip. As cells are shrunk to fit more bits on a chip, there are other effects to manage. This includes on-die errors; on-die error correction will start to become more prevalent than it is today. There are also other effects to address like RowHammer and RowPress, where accessing certain cells can disturb cells that are in neighboring areas.
There are adjacent developments to consider as well. The AI 2.0 era is rolling out at a time that we are simultaneously nearing the cusp of quantum computing. Quantum capable computers will introduce new challenges to protecting the data, algorithms and models that are foundational to AI 2.0 as well as the data and transactions underpinning our modern world. Quantum Safe Cryptography will be critical to protecting these valuable AI assets and the private data of consumers and enterprises.
Rambus Labs, for example, is researching some of these areas, as is the industry. We are very aware of the challenges facing the industry right now, and there are a lot of good minds working to address these issues. This will be key to ensuring that memory and interconnects can continue to provide the performance levels that the industry will need going forward for AI 2.0.

Leave a Reply