At Rambus, we create cutting-edge semiconductor and IP products, providing industry-leading chips and silicon IP to make data faster and safer.
CXL 2.0 Controller
Home > Interface IP > CXL Controller IP > CXL 2.0 Controller
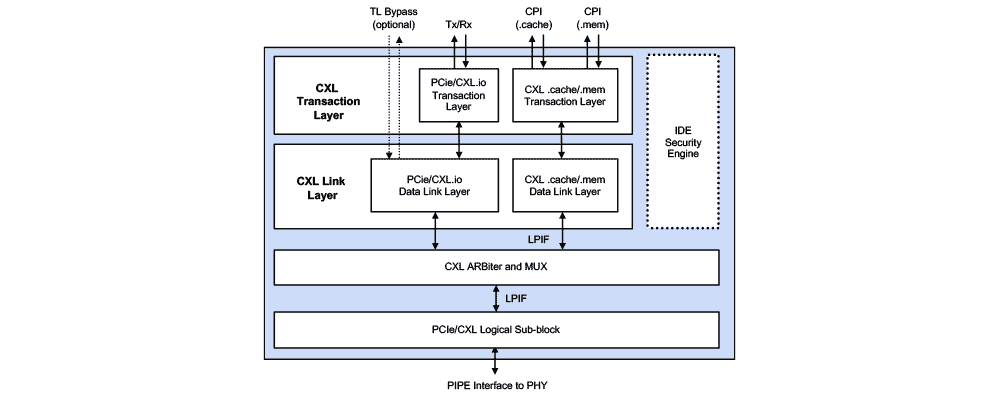
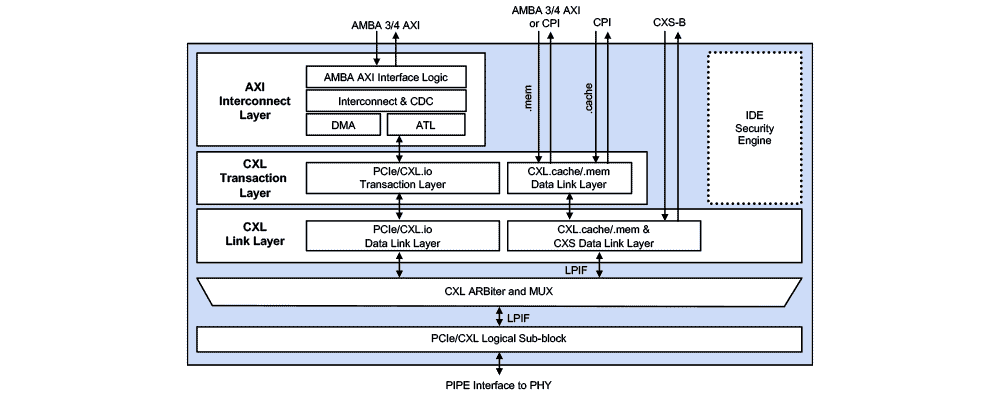
Rambus Compute Express Link™ (CXL™) 2.0 Controller (formerly XpressLINK) leverages a silicon-proven PCIe 5.0 controller architecture for the CXL.io path, and adds CXL.cache and CXL.mem paths specific to the CXL standard. The controller exposes a native Tx/Rx user interface for CXL.io traffic as well as an Intel CXL-cache/mem Protocol Interface (CPI) for CXL.mem and CXL.cache traffic. There is also an CXL 2.0 Controller with AXI version (formerly XpressLINK-SOC) for ASIC and FPGA implementations with support for the AMBA AXI protocol specification for CXL.io and either CPI or AXI for CXL.mem, and CPI for CXL.cache or the AMBA CXS-B protocol specification.
 Contact
Contact CXL 2.0
CXL 2.0How the CXL 2.0 Controller Works
The controller supports the CXL 2.0 specification and is backward compatible with CXL 1.1. It complies with the Intel PHY Interface for PCI Express (PIPE) specification version 5.x. The provided Graphical User Interface (GUI) Wizard allows designers to tailor the IP to their exact requirements, by enabling, disabling, and adjusting a vast array of parameters, including CXL device type, PIPE interface configuration, buffer sizes and latency, low power support, SR-IOV parameters, etc. for optimal throughput, latency, size and power. The controller has been extensively verified using commercial and internally developed VIP and test suites. It can be paired with a number of 3rd-party CXL PHYs.
Watch a video demo of our Controller IP for CXL 2.0 and the CXL.mem protocol used to access Host-managed Device Memory.
The CXL 2.0 controller has been extensively verified using commercial and internally developed VIP and test suites.
[Video] Demonstrating the Future: CXL Over Optics
In this demonstration, Olivier Alexandre, Senior Manager of Validation Engineering at Rambus, shows a Rambus CXL endpoint device connected to a Viavi Xgig 6P4 Exerciser using Samtec Firefly optic cable technology, effectively creating a remote “CXL Memory Expansion” block.
Solution Offerings
CXL 2.0 Controller
CXL Protocol Layer
- Comprises complete CXL 2.0 interconnect subsystem with Rambus CXL 2.0 PHY
- Supports the CXL 2.0 specification; backward compatible with CXL 1.1
- Implements the CXL.io, CXL.mem, and CXL.cache protocols
- Supports all 3 defined CXL device types
- Supports Host, Device, Switch ports and Dual Mode/shared silicon implementation
- Supports the PCI Express 5.0 base specification revision 1.0
- Supports the PIPE 5.x specification with 8, 16, 32, 64 and 128-bit configurable PIPE interface width
- Supports CXL device configurations
- Supports operation at x16, x8, x4, x2, x1
- Compliant with PCI-SIG Single-Root I/O Virtualization (SR-IOV) Specification
- Supports up to 64 Physical Functions (PF), 512 Virtual Functions (VF)
- Supports PCI Express Advanced Error Reporting (AER)
- Supports optional ECNs
- Supports Port Bifurcation
- Supports deferrable writes
- Supports DOE, CMA over DOE
User Interface Layer
- PLDA native 256/512-bit transmit/receive low-latency interface for CXL.io traffic
- Intel-defined CXL cache/mem Protocol Interface (CPI) for CXL.mem and CXL.cache traffic
- User-selectable Transaction/Application Layer clock frequency (CXL.io)
- Dedicated sideband interface for Reliability, Availability and Serviceability (RAS) features
Integrity and Data Encryption (IDE)
- AES-GCM security supports CXL.mem/CXL.cache at full line rate and with zero latency
- AES-GCM security IP supports PCIe/CXL.io to near full line rate with low latency
- Implements the CXL 2.0 IDE specifications for CXL.cache/mem
- Implements the PCI Express IDE ECN for CXL.io
- Configurable IDE engine
- Supports x1 to x16 lanes
- Supports all device types
- 256-bit or 512-bit data bus for PCIe IDE
- 512-bit data bus for CXL.cache/mem IDE
- Supports containment and skid modes
- Supports early MAC termination
- Supports multi-stream
- Utilizes high-performance AES-GCM for encryption, decryption, authentication
- PCIe IDE TLP aggregation for 1, 2, 4, 8 TLPs
- PCIe IDE automatic IDE prefix insertion and detection
- PCIe IDE automatic IDE sync/fail message generation
- PCRC calculation & validation
- Efficient key control/refresh
- Bypass mode
Unique Features & Capabilities
- Internal data path size automatically scales up or down (256, 512 bits) based on max. link speed and width for reduced gate count and optimal throughput
- Dynamically adjustable application layer frequency down to 8Mhz for increased power savings
- Optional MSI/MSI-X register remapping to memory for reduced gate count when SR-IOV is implemented
- Configurable pipelining enables full speed operation on Intel and Xilinx FPGA, full support for production FPGA designs (when supported)
- Ultra-low Transmit and Receive Buffer latency
- Use of highly optimized CPI interface for CXL.cache and CXL.mem to maximize throughput and minimize latency
- Smart buffer management on receive side (Rx Stream) allows implementation of custom credit management schemes in the application logic
- Merged Replay and Transmit buffer enables lower memory footprint
- Optional Transaction Layer bypass allows for customer specific transaction layer and application layer
- Optional QuickBoot mode allows for up to 4x faster link training, cutting system-level simulation time by 20%
CXL 2.0 Controller with AXI
CXL Protocol Layer
- Comprises complete CXL 2.0 interconnect subsystem with Rambus CXL 2.0 PHY
- Supports the CXL 2.0 specification; backward compatible with CXL 1.1 specification
- Implements the CXL.io, CXL.mem, and CXL.cache protocols
- Supports all 3 defined CXL device types
- Supports the PCI Express 5.0 base specification revision 1.0
- Supports the PIPE 5.x specification with 8, 16, 32, 64 and 128-bit configurable PIPE interface width
- Supports CXL device configurations
- Supports operation at x16, x8, x4, x2, x1
- Supports Host, Device, and Dual Mode/shared silicon implementation
- Supports Low-latency CXL.mem flit encoder/decoder
- Supports Viral error containment
- Supports deferrable writes
- Supports Standard Intel CPI interface or AMBA AXI for CXL.mem
- Supports Standard Intel CPI interface for CXL.cache
- Supports AMBA® CXS.B interface
- Supports Sync header bypass and drift buffer modes supported
- Supports All low-power states
- Supports CXL RAS features (including Viral and Data Poisoning)
- Supports Hot-Plug
- Supports Alternate Protocol Negotiation
- Supports RCiEP
- Supports DOE, CMA over DOE
AMBA AXI Layer for CXL.io
- Compliant with the AMBA® AXI™ Protocol Specification (AXI3, AXI4 and AXI4-Lite) and AMBA® 4 AXI4-Stream Protocol Specification
- Optional AXI4-Lite Slave interface for Bridge Configuration
- Optional AXI4-Lite Master interface for External Registers Configuration
- Optional AXI4 Master Descriptor interface to access SG-DMA Descriptors in AXI domain
- Up to 4 AXI4 Master interfaces, each supporting up to 128 outstanding read requests
- Up to 4 AXI4 Slave interfaces, each supporting up to 256 outstanding read requests
- Up to 4 AXI4 Stream Input and Output interfaces, each handling up to 8 TID/TDEST combinations simultaneously
- 64-bit, 128-bit, 256-bit, or 512-bit data support for AXI4 Master, Slave, and Stream interfaces
- Bypassable CDC for AXI4 Master, Slave, and Stream interfaces
- AXI4 Master and Slave interfaces can be configured as AXI3 interfaces
- Optional built-in Legacy DMA engine
- Up to 8 DMA channels, Scatter-Gather, descriptor prefetch
- Completion reordering, interrupt and descriptor reporting
- Optional Address Translation tables for direct PCIe to AXI and AXI to PCIe communication
Integrity and Data Encryption (IDE)
- AES-GCM security supports CXL.mem/CXL.cache at full line rate and with zero latency
- AES-GCM security IP supports PCIe/CXL.io to near full line rate with low latency
- Implements the CXL 2.0 IDE specifications for CXL.cache/mem
- Implements the PCI Express IDE ECN for CXL.io
- Configurable IDE engine
- Supports x1 to x16 lanes
- Supports all device types
- 256-bit or 512-bit data bus for PCIe IDE
- 512-bit data bus for CXL.cache/mem IDE
- Supports containment and skid modes
- Supports early MAC termination
- Supports multi-stream
- Utilizes high-performance AES-GCM for encryption, decryption, authentication
- PCIe IDE TLP aggregation for 1, 2, 4, 8 TLPs
- PCIe IDE automatic IDE prefix insertion and detection
- PCIe IDE automatic IDE sync/fail message generation
- PCRC calculation & validation
- Efficient key control/refresh
- Bypass mode
Unique Features & Capabilities
- Internal data path size automatically scales up or down (256, 512 bits) based on max. link speed and width for reduced gate count and optimal throughput
- Dynamically adjustable application layer frequency down to 8Mhz for increased power savings
- Optional MSI/MSI-X register remapping to memory for reduced gate count when SR-IOV is implemented
- Configurable pipelining enables full speed operation on Intel and Xilinx FPGA, full support for production FPGA designs (when supported)
- Ultra-low Transmit and Receive Buffer latency
- Use of highly optimized CPI interface for CXL.cache and CXL.mem to maximize throughput and minimize latency
- Merged Replay and Transmit buffer enables lower memory footprint
- Optional QuickBoot mode allows for up to 4x faster link training, cutting system-level simulation time by 20%
IP files
- Verilog RTL source code
- Libraries for functional simulation
- Configuration assistant GUI (Wizard)
Verification Environment
Documentation
Reference Design
- Synthesizable Verilog RTL source code
- Simulation environment and test scripts
- Synthesis project & constraint files
Advanced Design Integration Services:
- Integration of commercial and proprietary CXL PHY IP
- Customization of the Controller IP to add customer-specific features
- Generation of custom reference designs
- Generation of custom verification environments
- Design/architecture review and consulting
CXL Memory Interconnect Initiative: Enabling a New Era of Data Center Architecture

In response to an exponential growth in data, the industry is on the threshold of a groundbreaking architectural shift that will fundamentally change the performance, efficiency and cost of data centers around the globe. Server architecture, which has remained largely unchanged for decades, is taking a revolutionary step forward to address the growing demand for data and the voracious performance requirements of advanced workloads.


