The growing trend of multi-core processing and converged graphics-compute processors is increasing the performance requirements on the DRAM memory subsystems. Multi-thread computing and graphics not only need higher memory bandwidth but also generate more random accesses to smaller pieces of data. Module Threading improves the throughput and power efficiency of a memory module by applying parallelism to module data accesses. This innovation partitions the module into two individual memory channels and interleaves the commands to each respective channel. The result is a smaller minimum transfer size and reduced row activation power, translating to 50% higher bandwidth and 20% lower memory power compared to a conventional DIMM module.
- Improves memory throughput up to 50%
- Reduces power consumption by 20% for equivalent workloads versus conventional modules
- Enables full utilization of memory IO bandwidth
- Utilizes conventional DRAM
What is Module Threading Technology?
Multi-thread computing is driving up memory bandwidth, but needs smaller access granularity due to the random nature of the data accesses. However, small transfers of data are becoming increasingly difficult with each DRAM generation. Although the memory interface has become faster, the frequency of the main memory core has remained relatively the same. As a result, DRAMs implement core prefetch where a larger amount of data is sensed from the memory core and then serialized to a faster off-chip interface, effectively increasing the access granularity. This discrepancy between the interface speed and the core speed translates to a core-prefetch ratio of 8:1 in current DDR3 DRAMs, and is forecasted to reach 16:1 in future DRAM. This larger prefetch ratio and transfer size can lead to computing inefficiency, especially on multi-threaded and graphics workloads with the need for increased access rate to smaller pieces of data.
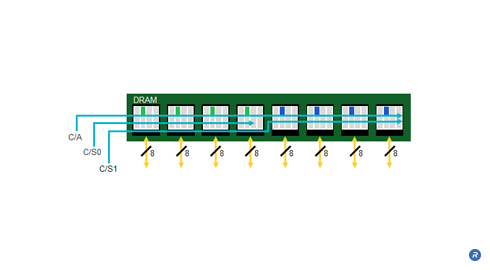
The memory subsystem in today’s computing platforms are typically implemented with DIMMs that have a 64bit-wide data bus and a 28bit command/address/clock bus. On a standard DDR3 DIMM module, all the devices within a module rank are accessed simultaneously with a single Command/Address (C/A). An example module configuration places eight (x8) DDR3 components assembled in parallel onto a module printed circuit board and has a minimum efficient data transfer of 64Bytes.
Greater efficiency with a multi-threaded workload and smaller transfers can be achieved by partitioning the module into two separate memory channels, and multiplexing the commands across the same set of traces as a traditional module but with separate chip selects for each respective memory channel. In threaded module, each side of the module is accessed independently, thereby reducing the minimum transfer size to one-half the amount of a standard single-channel module.
Threaded modules can lower the power of main memory accesses. For a conventional eight-device module, all eight DRAMs are activated (ACT) followed by a read or write (COL) operation on all eight devices. A threaded or dual-channel module can accomplish the same data transfer by activating only four devices and then performing two consecutive read or write operations to those devices. Since only four devices are activated per access instead of eight devices, a threaded or dual-channel module achieves equivalent bandwidth with one-half the device row activation power. On a memory system, this translates to approximately 20% reduced total module power.
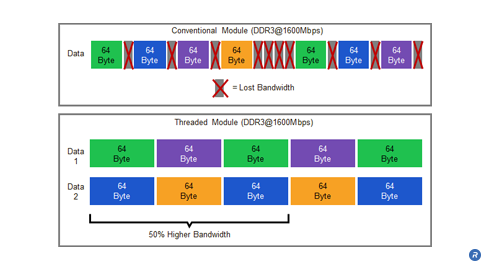
Another benefit that threaded modules offer is increased sustained bandwidth at high data rates. Many modern industry-standard DRAMs have limited bandwidth due to power restrictions on the DRAM devices. On DRAMs starting with the DDR3 generation, only a limited number of banks may be accessed in order to protect the on–DRAM power delivery network and maintain a stable voltage for the memory core. This parameter, know as tFAW (Four Activate Window period) allows only 4 banks to be activated in the rolling tFAW window.
For a computing system, tFAW restricts the memory controller from issuing additional row activate commands once four activates have already been issued in a given tFAW period. This stalls the memory controller and results in lost data bandwidth. A DDR3 DRAM running at 1600Mbps data rates loses up to 50% of its sustained data bandwidth due to this and other restrictions. Since the DRAMs in a threaded module are activated half as often as those in a conventional module, the sustained bandwidth of a threaded module is not limited by the core parameters.
Who Benefits?
Module threading delivers system designers the benefits of increased bandwidth from improved transfer efficiency and smaller access granularity, while maintaining the commodity cost structure of the module. End users can benefit from the 50% improvement in throughput performance as well as the 20% reduction in total memory power.