Today (Nov. 14th, 2023) the CXL™ Consortium announced the continued evolution of the Compute Express Link™ standard with the release of the 3.1 specification. CXL 3.1, backward compatible with all previous generations, improves fabric manageability, further optimizes resource utilization, enables trusted compute environments, extends memory sharing and pooling to avoid stranded memory, and facilitates memory sharing between accelerators. When deployed, these improvements will boost the performance of AI and other demanding compute workloads.
Supercomputing 2023 (SC23), going on this week in Denver, provided the perfect backdrop for announcing this latest advancement in the CXL standard. At SC23, the Consortium is hosting demos from 16 ecosystem partners at the CXL pavilion (Booth #1301) including Rambus. There, we’re demonstrating the newly-announced Rambus CXL Platform Development Kit (PDK) performing memory tiering operations.
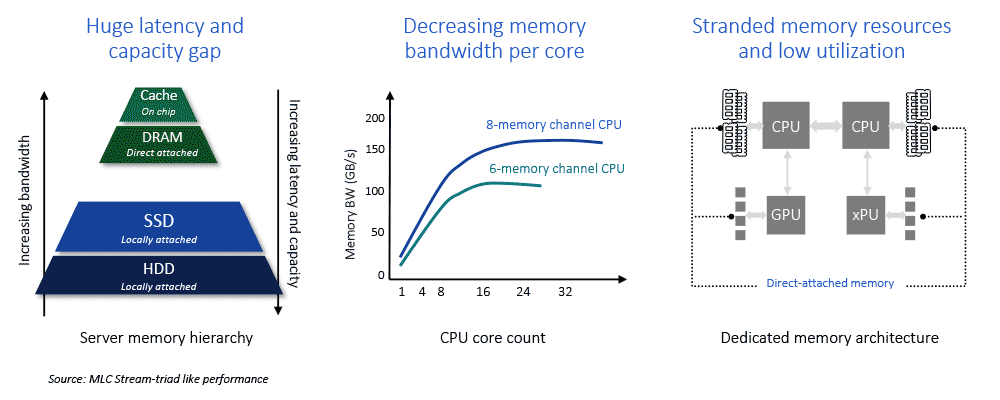
CXL memory tiering tackles one of the biggest hurdles for data center computing: namely the three order of magnitude latency gap that exists between direct-attached DRAM and Solid-State Drive (SSD) storage. When a processor runs out of capacity in DRAM main memory, it must go to SSD, which leaves the processor waiting. That waiting, or latency, has a dramatic negative impact on computing performance.
Two other big problems arise from 1) the rapid scaling of core counts in multi-core processors and 2) the move to accelerated computing with purpose-built GPUs, DPUs, etc. Core counts are rising far faster than main memory channels, with the upshot being that cores past a certain number are starved for memory bandwidth, sub-optimizing the benefit of those additional cores. With accelerated computing, a growing number of processors and accelerators have direct-attached memory to provide higher performance, but more independent pockets of memory leads to a higher probability of memory resources being underutilized or stranded.
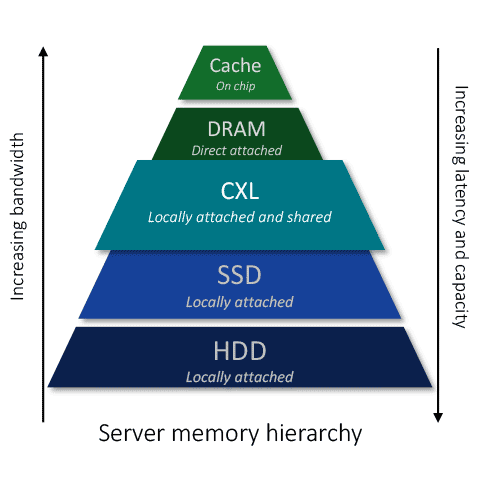
CXL Memory Tiering Can Bridge the Latency Gap
CXL promises to address all three of these challenges. CXL enables new memory tiers which bridge the latency gap between direct-attached memory and SSD, and provide greater memory bandwidth to unlock the power of multi-core processors. In addition, CXL allows memory resources to be shared among processors and accelerators addressing the stranded memory challenge.

Delivering on the promise of CXL requires a great deal of co-design of solutions across the ecosystem spanning chips, IP, devices, systems and software. That’s where tools like the Rambus CXL PDK can make a major contribution. The PDK enables module and system makers to prototype and test CXL-based memory expansion and pooling solutions for AI infrastructure and other advanced systems. Interoperable with CXL 1.1 and CXL 2.0 capable processors, and memory from all the major memory suppliers, it leverages today’s available hardware to accelerate the development of the full stack of CXL-based solutions slated for deployment in a few years’ time.
For more information about the Rambus CXL PDK check out the Rambus CXL Memory Initiative here.
Leave a Reply