Written by Steven Woo
As we’ve discussed in previous Rambus blog posts, high-performance computing (HPC) memory bandwidth and capacity are continuing to fall further and further behind the performance of compute engines. Consequently, memory and I/O subsystems are becoming increasingly larger bottlenecks that must be carefully managed by applications and operating systems. There is also an increasing emphasis on improving HPC power efficiency, which in turn, is driving the demand for more power-efficient memory systems that achieve higher memory bandwidths and capacities – without increasing power.
Created by Horst Simon in a widely-recognized presentation about the difficulties and challenges with achieving Exascale computing targets, the image below illustrates the energy trends of computation and data movement. As of 2013, FLOPs were still more expensive than on-chip data movement in terms of energy per bit.
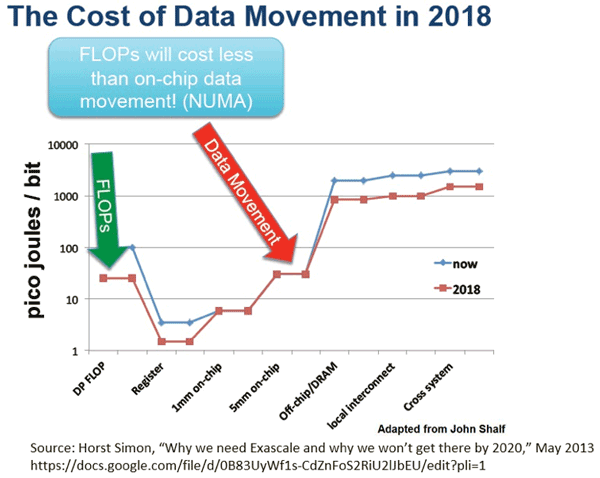
However, the projection for 2018 (at that time) was for the energy per bit of on-chip data movement to exceed that of computation. In 2013 (and projections for 2018), the energy per bit of off-chip/DRAM communication and long-distance data movement (local interconnects, longer-distance networking) exceeds that of computation by at least an order of magnitude.
Reassessing the HPC Memory Paradigm
The current memory hierarchy paradigm that supports massively parallel systems has become a major concern for the HPC sector. As we noted above, there is an increasing emphasis on improving HPC power efficiency, which in turn, is driving the demand for higher memory bandwidths and capacities without increasing power. The desire to increase memory capacity per processor core will put additional pressure on power budgets, which could in turn impact the way in which applications and architectures scale in the future. Scaling will be further strained as data movement continues to become a limiter in terms of power and performance. Moving forward, HPC architectures will need to minimize data movement, while also improving the power efficiency and performance of memory interfaces and chip-to-chip links.
HPC and HBM
Coupled with the high cost of power associated with data movement, supercomputer system architects are looking at new solutions for addressing the need for more memory system performance with improved power efficiency. Although HBM memory is more challenging to design into systems than other memories such as DDR and GDDR, it is being introduced into future high-performance computing systems in Japan to address the critical memory system needs of performance and power-efficiency.
For example, the Post-K Supercomputer will be comprised of nodes powered by Fujitsu’s A64FX CPU connected to four HBM DRAMs serving as the processor main memory. The NEC SX-Aurora Tsubasa platform provides a scalable computing solution capable of supercomputer-class performance using the company’s new Vector Engine card. The A500-64 supercomputer, built around this platform, uses 64 Vector Engines that include a high-performance vector processor connected to six HBM DRAMs that provide unprecedented levels of memory bandwidth. These systems illustrate that there are compelling advantages to using HBM in high-performance computing applications.
Leave a Reply