A recent paper published on arXiv by a team of UC Berkeley researchers observes that neural networks are increasingly bottlenecked and constrained by the limited capacity of on-device GPU memory. Indeed, deep learning is constantly testing the limits of memory capacity on neural network accelerators as neural networks train with high-resolution images, 3D point-clouds and long Natural Language Processing (NLP) sequence data.
“In these applications, GPU memory usage is dominated by the intermediate activation tensors needed for backpropagation. The limited availability of high bandwidth on-device memory creates a memory wall that stifles exploration of novel architectures,” the researchers explain. “One of the main challenges when training large neural networks is the limited capacity of high-bandwidth memory on accelerators such as GPUs and TPUs. Critically, the bottleneck for state-of-the-art model development is now memory rather than data and compute availability and we expect this trend to worsen in the near future.”
As the researchers point out, some initiatives to address this bottleneck focus on dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs. As such, the UC Berkeley team uses off-the-shelf numerical solvers to formulate optimal rematerialization strategies for arbitrary deep neural networks in TensorFlow with non-uniform computation and memory costs. In addition, the UC Berkeley team demonstrates how optimal rematerialization enables larger batch sizes and substantially reduced memory usage – with minimal computational overhead across a range of image classification and semantic segmentation architectures.
“Our approach allows researchers to easily explore larger models, at larger batch sizes, on more complex signals with minimal computation overhead,” says the UC Berkeley team.
Specifically, the paper published by the UC Berkeley team on arXiv describes a formalization of the rematerialization problem as a mixed integer linear program with significantly more flexible search space than prior work. As well, it details an algorithm to translate a feasible solution into a concrete execution plan and a static training graph – and describes an implementation of optimal tensor rematerialization in Tensorflow at runtime. Finally, it introduces Checkmate, a system that enables training models with up to 5.1× larger input sizes and up to 2.6× larger batch sizes (than prior art) at minimal overhead.
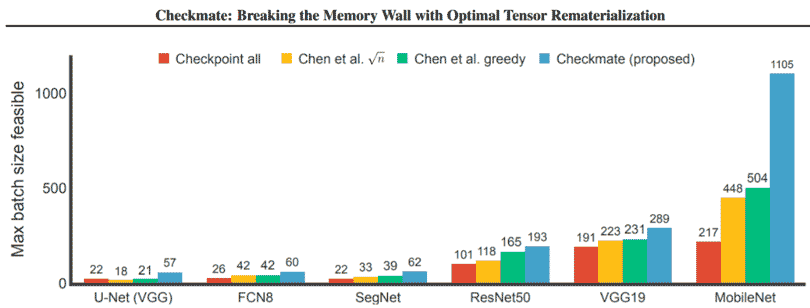
Image Credit: Department of EECS, UC Berkeley
“Checkmate enables practitioners to train a high-resolution U-Net on a single V100 GPU with an unprecedented batch size of 57, as well as batch size of 1105 for MobileNet,” the UC Berkeley team states. “The former is 2.6× larger than the maximum batch size with prior art. Checkmate … solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations.”
The UC Berkeley research team also notes that its method scales to complex, realistic architectures and is hardware-aware via the use of accelerator-specific, profile-based cost models.
“In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1× larger input sizes,” they conclude.
Commenting on the above, Steven Woo, Rambus fellow and distinguished inventor, states: “The work of the team at UC Berkeley is focused on one of the key problems facing neural networks today – how to keep up with the trend of using larger models and training sets that are growing faster than the memory capacity of individual hardware accelerators can scale. Distributing the training among multiple accelerators is one method, but communication between the accelerators reduces performance and increases the energy used. There is a clear need to do more on each accelerator if possible.”
Leave a Reply