[fullwidth background_color=”” background_image=”” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ background_repeat=”no-repeat” background_position=”left top” video_url=”” video_aspect_ratio=”16:9″ video_webm=”” video_mp4=”” video_ogv=”” video_preview_image=”” overlay_color=”” overlay_opacity=”0.5″ video_mute=”yes” video_loop=”yes” fade=”no” border_size=”0px” border_color=”” border_style=”” padding_top=”20″ padding_bottom=”20″ padding_left=”0″ padding_right=”0″ hundred_percent=”no” equal_height_columns=”no” hide_on_mobile=”no” menu_anchor=”” class=”” id=””][one_full last=”yes” spacing=”yes” center_content=”no” hide_on_mobile=”no” background_color=”” background_image=”” background_repeat=”no-repeat” background_position=”left top” border_position=”all” border_size=”0px” border_color=”” border_style=”” padding=”” margin_top=”” margin_bottom=”” animation_type=”” animation_direction=”” animation_speed=”0.1″ class=”” id=””][fusion_text]Enables very high bandwidth on next generation memory systems. Signal equalization is applied asymmetrically across the memory PHY and DRAM communication link and improves overall signal integrity while minimizing the complexity and cost of the DRAM device. [Read more…] about Asymmetric Equalization
Memory + Interfaces
Very Low-Swing Differential Signaling
Today’s mobile device demand high bandwidth for HD video capture and streaming, and media-rich web browsing as well as extended battery life. Very Low-Swing Differential Signaling (VLSD) is a bi-directional, ground-referenced, differential signaling technology which offers a high-performance, low-power, and cost-effective solution for applications requiring extraordinary bandwidth and superior power efficiency.
- Enables high data rates at very low IO power consumption
- Improves signal integrity
What is Very Low-Swing Differential Signaling Technology?
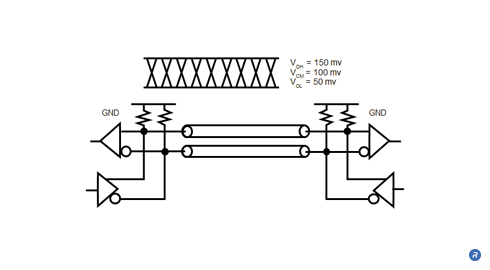
VLSD signals are point-to-point and use an ultra-low 100mV signal swing (50 to 150mV) and 100mV common-mode voltage, which results in a 200mV peak-to-peak differential signal swing. This swing is less than 1/10th the signaling swing of commodity memory interfaces. VLSD enables high data rates with very low IO power consumption.
Who Benefits?
VLSD enables system designers to achieve high-speed operation through the robust signaling characteristics inherent to differential signaling, while minimizing IO power consumption through the use of a ground-referenced low-voltage-swing signaling system. This combination of high-bandwidth and low-power operation improves mobile device performance and battery life for consumers.
On Die Termination Calibration
As the performance requirements of digital systems continue to increase, there are increasing requirements to deliver signal integrity that enables reliable operation at higher signaling rates. Signal line terminations are useful elements in the management of signal integrity, and can be use external to the memory device or within the device itself. Incorporating a resistive termination within the DRAM device, which is often referred to as On Die Termination (ODT), improves the signaling environment by reducing the electrical discontinuities introduced with off-die termination. However, variations across process, voltage and temperature (PVT) can cause instability in the resistive characteristics of the ODT elements. Rambus ODT Calibration determines an optimal termination impedance to reduce signal reflections and compensate for variations across PVT.
- Calibrates ODT termination impedance
- Reduces signal reflections
- Compensates for variations across PVT and operating conditions
What is On Die Termination Calibration Technology?
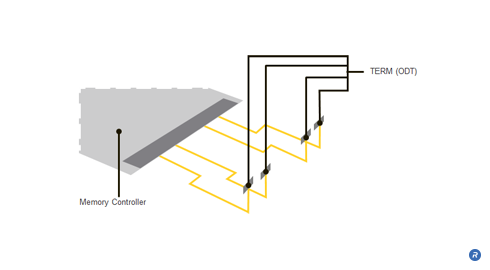
Conventional DRAM memory module architectures typically include line termination resistors on the motherboard. Although the termination resistors on the motherboard reduce some reflections on the signal lines, they are unable to prevent reflections resulting from the stub lines that connect to the DRAMs on the module. A signal propagating from the memory controller to the DRAM encounters an impedance discontinuity at the stub leading to the DRAM on the module. The signal that propagates along the stub to the DRAM will be reflected back onto the signal line, thereby introducing unwanted noise into the signal. The introduced noise and the consequential signal degradations that are not addressed by such off-die termination become more pronounced with higher data rates and longer stub lengths. Larger, multi-drop systems containing multiple DRAM modules introduce even more reflections and consequently add more reflective noise, thereby resulting in further signal degradation.
By placing the termination resistance on the die itself rather than the motherboard, the reflections resulting from discontinuities in the line are significantly reduced, thus producing a cleaner signal and enabling faster data rates.
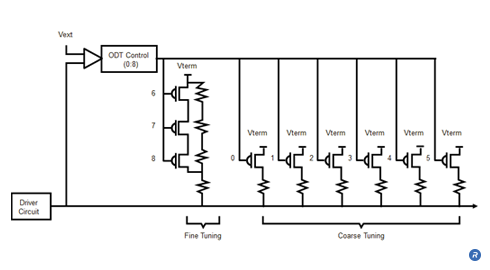
ODT calibration is a technique that involves calibrating the termination impedance in order to optimize the reduction of signal reflections. ODT calibration allows an optimal termination value to be established that compensates for variations in process and operating conditions.
A calibrated ODT value significantly reduces unwanted signal reflections while only minimally attenuating the magnitude of the signal swing due to the added resistive loading. The resulting cleaner data signal allows for higher data rates.
ODT calibration is achieved by establishing an ODT impedance that is proportional to an external precision resistor. The same external resistor can also be used for Output Driver Calibration.
The ODT calibration controller, compares the voltage drop across the ODT resistor network with a voltage drop across an external resistor represented. The controller modifies the resistor network with coarse tuning and fine tuning to achieve an impedance value that closely approximates the external, reference resistance.
Who Benefits?
ODT calibration delivers benefits at the device, subsystem and system level. By implementing ODT calibration, devices are able to achieve enhanced signal performance and higher data rates, which enables designers to achieve superior DRAM device and module performance.
In addition, placing the termination components on the DRAM devices removes these elements from the PCB. In doing so, the number of components and signal lines on the motherboard is reduced, lowering the cost and complexity while increasing reliability.
Finally, the system benefits from the superior data rates and module performance that are enabled through the improved signal integrity achieved with ODT calibration.
Micro-Threading Technology
Improvements in DRAM interface throughput have rapidly outpaced comparable improvements in core speeds. Whereas data rates of DRAM interfaces have increased by over an order of magnitude over successive generations, the DRAM core frequency has remained relatively constant. Over time, core prefetch size has increased in order to keep pace with improvements in interface bandwidth. However, larger prefetch sizes increase access granularity—a measure of the amount of data being processed—and deliver more data than necessary, causing processing inefficiencies. Micro-threading is a unique DRAM core access architecture that improves transfer efficiency and effective use of DRAM architecture resources by reducing row and column access granularity. By providing independent addressability to each quadrant of the DRAM core, micro threading allows minimum transfer sizes to be four times smaller than typical DRAM devices, complementing the threaded memory workloads of modern graphics and multi-core processors. This unique architecture enables micro-threading to maintain the total data bandwidth of the device while reducing power consumption per transaction.
- Improves transfer efficiency for multi-core computing applications
- Doubles DRAM core data rate versus conventional techniques
- Maintains high sustained bandwidth while lowering power consumption
What is Micro-threading Technology?
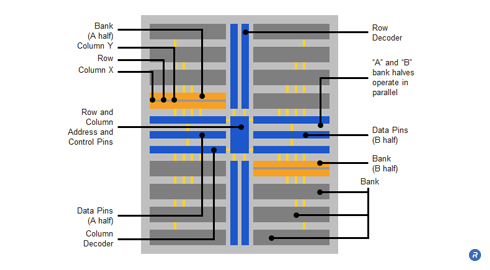
Access granularity is a function of the accessibility of data within a memory architecture. A typical DRAM is comprised of eight storage banks. Within such DRAMs, each bank is typically further subdivided into two half banks, “A” and “B”. For such a DRAM with 32 data pins, each A half bank is connected to 16 data pins and each B half bank is connected to 16 pins. The banks are in opposite quadrants of the physical die, and each quadrant has its own dedicated row and column circuitry – each bank half operating in parallel in response to the row and column commands.
A row command selects a single row in each bank half of the bank being addressed, thereby sensing and latching that row. Physical timing constraints impose a delay (i.e., tRR) before a row in another bank can be accessed. Column commands are similarly constrained (i.e., tCC). However, the row timing interval is typically twice the column timing interval; therefore two column commands can be issued during the mandatory delay required for a single row activation.
The column prefetch length, the amount of data delivered per transaction, is determined by the respective column and row timing delays and bit transfer rate, where:
Prefetch = timing delay/bit transfer rate
A core of a mainstream DRAM typically operates up to 200MHz, whereas a core of a high performance industry standard DRAM can typically operate up to 400MHz. Core frequencies exceeding 400MHz are difficult to achieve using modern industry standard DRAM technologies without sacrificing production yields or increasing costs. Therefore, a column prefetch of 16bit is required for such a high performance DRAM core to support external data rates exceeding 3200 MHz since the DRAM cores is organized with each half-bank operating under the same row or column operation
In addition:
Column granularity = (column prefetch) x (number of data pins per half bank) x (number of half banks per access)
Or:
For a 32-bit wide DRAM with 16 data pins per half bank:
Column granularity per access = 16 x 16 x 2 = 512 bits or 64 bytes.
Moreover, during the row timing interval, in order to maintain peak bandwidth, at least two column operations must be performed. This is typically described as two column address strobes per row address strobe (two CAS per RAS). This results in a minimum row granularity of 128 bytes. This large access granularity translates into inefficient data and power utilization for applications such as 3D graphics.
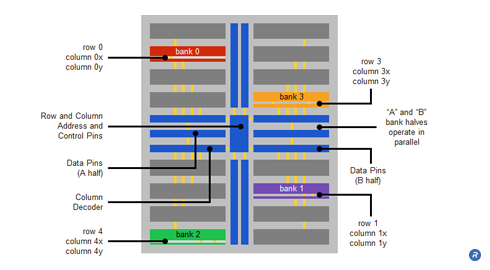
Using largely the same core resources as in the previous example, a sample micro-threaded DRAM core has 16 banks, each bank in the micro-threaded DRAM being equivalent to a half bank in the typical DRAM core. The even numbered banks connect to the A data pins and odd numbered banks connect to the B data pins (again with 16 pins in each case). However, unlike a typical core, each four-bank quadrant can operate independently, through the use of independent row and column circuitry for each quadrant. Moreover, interleaving, simultaneous access to more than one bank of memory, allows concurrent accesses to the lower quadrant on the same physical side of the core as the previous access.
Micro-threading enables four independent accesses to the DRAM core simultaneously. Although the same time interval as a typical core must still elapse before accessing a second row in a particular bank or bank quadrant, the three banks in the other quadrants remain separately accessible during the same period. Columns in rows in other quadrants can be concurrently accessed even though a column timing interval must pass before a second column is accessible in the previously activated row. The net effect of this quadrant independence and interleaving is that four rows (one in a bank of each quadrant) and eight columns (two in each row) are accessed during the row timing interval (compared to a single row and two columns with the typical DRAM technique).
Timings are similar to the typical DRAM core, but each column only sends data for half the column timing interval. The interleaved column sends data for the other half of the interval. Micro-threading reduces minimum transfer granularity size while maintaining a high-yielding and cost effective core frequency. By interleaving the column accesses from four different banks, a micro-threaded DRAM core (of a given column prefetch length and core frequency) can support data rate two times higher than that of a conventional DRAM core. Conversely, micro-threading of the column operation enables a DRAM core to cost-effectively sustain a specific data transfer and granularity while relaxing the column cycle time (tCC) by up to two times compared to those of a conventional DRAM core.
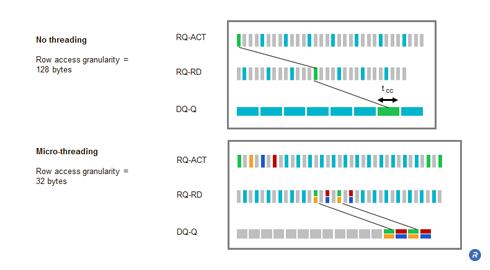
With micro-threading, column granularity is now:
Column prefetch/2 x 16 pins = 16/2 x 16 = 128 bits or 16 bytes (one quarter of the previous value).
The row granularity is 32 bytes (again one quarter of the previous value). Micro-threading’s finer granularity results in a performance boost in many applications. For example, in a graphics application with 8 byte micro-threaded column access granularity, computational and power efficiency increased from 29 percent to 67 percent after introducing the technique.
Who Benefits?
Micro threading enables twice the data rate from a DRAM core over conventional techniques, providing memory system designers high sustained bandwidth while lowering power consumption. In addition, micro threading benefits DRAM designers and manufacturers by providing an alternative approach to improve efficiency and reduce access granularity using largely the same DRAM core, reducing cost and risk.
Fully Differential Memory Architecture
As data rates continue to increase, signal and power integrity are increasingly difficult to maintain in memory systems with single-ended signaling topologies. To enhance signal integrity and noise immunity across all communications between the memory PHY and the DRAM devices, Rambus implemented a Fully Differential Memory Architecture (FDMA) using a point-to-point topology, for data, clock, and command/address (C/A) channels. FDMA inherently reduces interference noise from simultaneous switching outputs (SSO) and crosstalk. Further, it reduces the EMI that would otherwise be generated in a single-ended system operating at the same data rate or frequency. With these advantages, FDMA enables very high-speed data transmission supported by full-speed operation of C/A channels.
- Enables low-power, high-performance memory systems
- Simplifies system design
- Increases system reliability through improved noise immunity
What is a Fully Differential Memory Architecture?
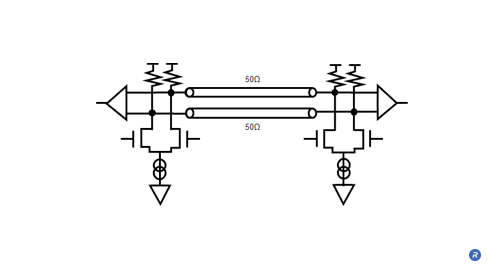
Differential signaling uses two wires for each signal (bit). A complementary signal is transmitted on one line or the other using a small DC current. The current is passed through a resistor on each line to generate a voltage, the difference being measured at the receiver. Depending on the polarity, the signal is interpreted as a “1” or “0”. SSO noise, a function of the cumulative value of the total amount of current change, is reduced because the same amount of current is generated regardless of the bit’s value.
A further advantage of differential signaling is that for a given voltage at the transmitter, twice the voltage difference is measured at the receiver (the difference in voltage between the two wires in the current loop). This compares with single-ended signaling that exhibits the same voltage at the transmitter and receiver (the difference between the voltage on the wire and ground). Twice the voltage at the receiver means it takes twice as much noise to exceed the threshold of a valid voltage level.
In addition, differential signaling has superior noise immunity when compared to single-ended signaling due to its inherent common mode noise rejection. Any voltage noise that couples into one wire of a pair is likely to couple into the other. Because the difference between the two signals is measured at the receiver, the common noise components are effectively cancelled out. In addition to being less susceptible to noise, differential signal pairs create less EMI than single-ended signals. This is because changes in signal level in the two wires create opposing electromagnetic fields that superimpose and cancel each other out, reducing crosstalk and spurious emissions.
Who Benefits?
FDMA offers a scalable architecture for delivering memory system bandwidth performance up to and beyond one terabyte per second. It supports a lower operating power at any given data rate since lower voltage levels than those required in a single-ended system can be used to maintain sufficient signal integrity. Further, FDMA simplifies overall system design and increases reliability by harnessing differential signaling advantages of superior noise immunity and lower EMI generation.
Fly-by Command Address
Conventional, low-speed DRAM systems distribute clock, command, and address signals to multiple DRAMs using a topology in which those signals propagate to all of the DRAMs in the system at approximately the same time. In such systems, the propagation delays on the command and address lines introduce timing skew into the system, thereby limiting the operating frequency of the bus and ultimately impacting the performance of high speed memory systems. In addition, the performance of these topologies is also limited by capacitive loading. Both the flight time skew problem and the capacitive loading issues discussed above through the use of the Fly-by architecture. Fly-by command/address architectures improve signal integrity in memory systems, thus enabling higher per-pin bit rates and systems capable of GHz data rates while maintaining low latency, and avoiding the need for clock-encoding.
- Improves signal integrity and overall system performance
- Simplifies system design with relaxed timing constraints
What is Fly-by Command Address Technology?
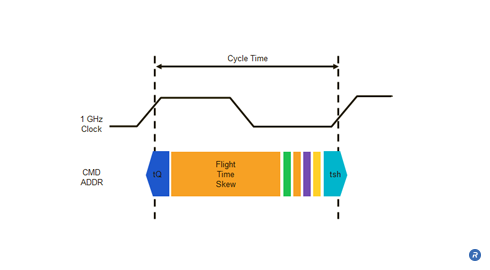
Although the skew in the clock, command, and address arrival times at each DRAM is small, the skew becomes significant as clock frequencies continue to increase. In such systems, the frequency limitations on the Command /Address (C/A) bus that result from the skew become a limiting factor in trying to achieve reliable GHz-speed memory operation performance.
The variability in flight time from the memory controller to the memory devices, or “flight time skew”, can become a significant factor in high frequency systems with short clock periods. As shown, the flight time skew can consume a large portion of the available cycle time such that when operating at speeds greater than 1 GHz, very little time is left for reliable signal set-up and hold times. The issue is further compounded when operating at double data rates.
In trying to address the problem of flight time skew, a common solution is to try to match the trace lengths of the signal lines used to convey the command and address signals. One technique that tries to do such trace matching relies on a forked topology. In a forked topology, such as that illustrated below, the command, address, and clock signal traces are routed to a central node and then distributed from the central node to the individual DRAMs. By providing a signal distribution point closer to the DRAMs, the potential variability in trace length is limited to the shorter paths from the central node to the individual DRAMs.
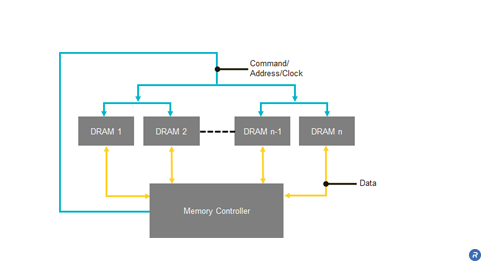
Additionally, the performance of conventional DRAM topologies is constrained by capacitive loading. Adding memory devices to increase memory capacity on the module increases the capacitive loading of the C/A lines, thereby limiting the signaling rate on the C/A line.
Rambus patented innovations address both the flight time skew problem and the capacitive loading issues discussed above through the use of the Fly-by architecture. The Fly-by architecture was incorporated in Rambus DRAM systems as a means to enable increased memory capacity without impacting memory data rates. The Fly-by architecture optimizes the system transmission topology, is tolerant of timing skews and, when used in combination with FlexPhase™ circuit technology, can further manage any skew issues. Fly-by enables point-to-point data lines with scalable capacity without compromising memory data rates.
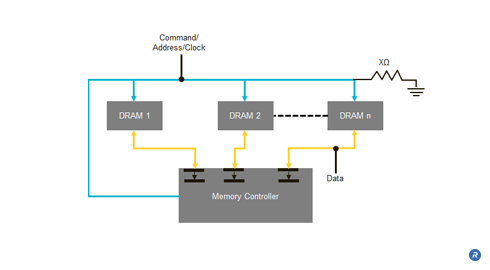
In the Fly-by architecture the clock, address, and command are transmitted source synchronously to the DRAMs. As shown in the figure above, the clock signal propagates with the address and control information such that those signals arrive together at the interface of each DRAM. However, in this topology, the set of signals propagating on those lines arrives at each DRAM at a slightly different time. As can be seen from the illustration above, the signals will arrive at DRAM 1 shortly before DRAM 2 and so on. Because the arrival times of the signals at the DRAM interfaces are distributed in time, the time at which the signals encounter the input capacitance of each of the DRAMs is similarly distributed, thus reducing the capacitive loading issues discussed above. The reduced capacitive loading enhances the signal integrity and enables higher data rate signaling.
Further increases in data rates can be achieved by employing FlexPhase circuit technology to the data signals at the memory controller. Because the arrival times of the control and address signals at the DRAMs are distributed in time, the resulting data traffic received from the DRAMs on the separate data lines will also be slightly skewed in time. FlexPhase circuitry can be used to de-skew these incoming data signals. FlexPhase circuitry can also be used to pre-skew the data signals driven from the controller to the DRAMs so the data arrives with a well understood timing relationship with respect to the command and address signals.
The Fly-by Command Address architecture can also use routing traces on the circuit board that are terminated in order to achieve better controlled impedance on the line than would be realized using other topologies. Additional impedance mismatch reduction can be achieved by having shorter stub lengths from the command/address line to each DRAM device on the memory module. The improved impedance characteristics of the signal lines results in smaller signal reflections and less noise, which in turn enables higher frequency signaling.
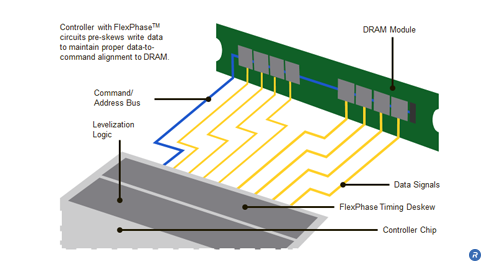
In addition to providing higher data rates, another significant advantage of the Fly-by approach is that it is highly scalable in that multiple additional DRAMs can be inserted in a system to meet the needs of the relevant applications. With the added DRAMs, the Fly-by architecture is able to maintain high data rates on the Command/Address/Clock signals, whereas other topologies are limited by flight time skew, capacitive loading and impedance mismatches. Such non-Fly-by topologies often must reduce signaling rates on the Command/Address lines to accommodate the added DRAMs, thereby reducing system performance.
When used with FlexPhase circuit technology, the Fly-by architecture allows designers to relax PCB trace length requirements because the timing variations can be managed on the memory module with the FlexPhase circuit technology. Rambus has also developed Dynamic Point to Point technologies that, when used in combination with Fly-by, enable memory upgrades while maintaining bandwidth.
Who Benefits?
Fly-by architectures enable subsystems that require operational data rates that are significantly greater than those achievable with conventional approaches. Using Fly-by architectures allows designers to relax PCB trace length requirements allowing much simpler and more compact memory sub-system layouts.
In addition, Fly-by architectures provide system benefits by enabling DRAM systems to operate with GHz data rates. This superior DRAM system performance results in improved performance in desktops, notebooks, enterprise servers and storage, HDTVs, gaming systems, and handheld portable devices for end users.