Ed Sperling of Semiconductor Engineering recently noted that new memory types and approaches are being developed as Moore’s Law begins to slow.
“What fits where in the memory hierarchy is becoming less clear as the semiconductor industry grapples with these changes,” he explained. “New architectures, such as fan-outs and 2.5D, raise questions about how many levels of cache need to be on-die, and whether high-speed connections and shorter distances can provide equal or better performance off-chip.”
According to Steven Woo, VP of Solutions Marketing at Rambus, the market is going down the path of scaling out to more servers.
“The problem is that the data is distributed among so many servers that you risk a long reach across high-latency networks to get that data. We’ve looked at a number of ways to change that equation,” he told the publication. “One of the solutions we’re experimenting with is cards with FPGA flexibility that include 24 DIMM modules. So you may have 1 card with 1.5 terabytes of data on a single card. That allows you to execute portions of the program right up against memory.”
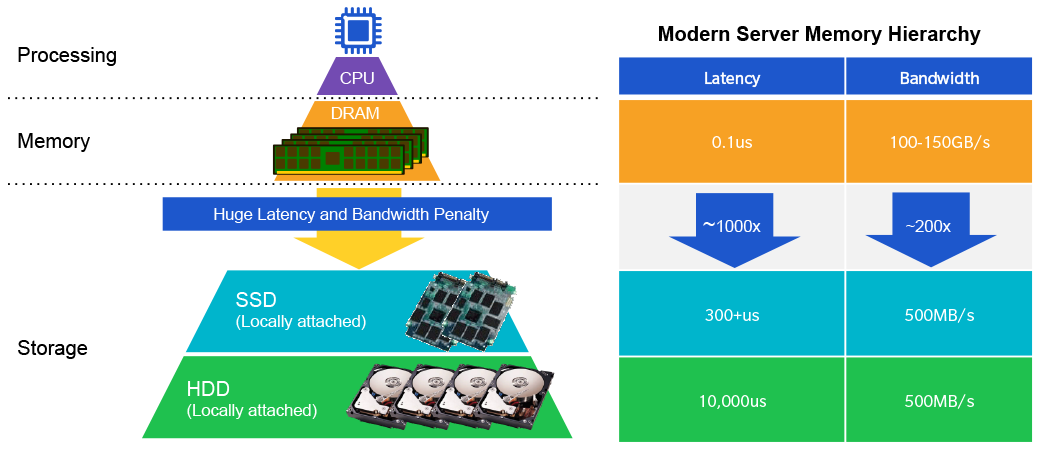
As Sperling points out, this represents a radically different way of looking at how and where large amounts of data are stored and accessed. One potential approach is to move these massive memory cards inside of server racks, significantly reducing the distance the data needs to travel.
“You used to drag data to the processor,” Woo said. “That worked fine when there was not as much data. But now we’ve got terabytes and petabytes of data, and the slowest approach is to move that data around. It’s much more efficient to move the computation to the data.”
Indeed, as we’ve previously discussed on Rambus Press, Rambus’ Smart Data Acceleration (SDA) research platform focuses on architectures designed to offload computing closer to very large data sets at multiple points in the memory and storage hierarchy. Potential use case scenarios include real-time risk analytics, ad serving, neural imaging, transcoding and genome mapping.
Comprising software, firmware, FPGAs and significant amounts of memory, the platform operates as an effective test bed for new methods of optimizing and accelerating analytics in extremely large data sets. As such, the SDA’s versatile combination of hardware, software, firmware, drivers and bit files can be precisely tweaked to facilitate architectural exploration of specific applications.

Currently, the SDA’s base extensible command set is targeted at accelerating and offloading the transformation of common data structures such as those found in Big Data analytics applications. However, the Smart Data Acceleration platform could ultimately be made available over a network where it would serve as a key offload agent in a more disaggregated scenario.
Interested in learning more? You can check out our official Smart Data Acceleration page here.
Leave a Reply