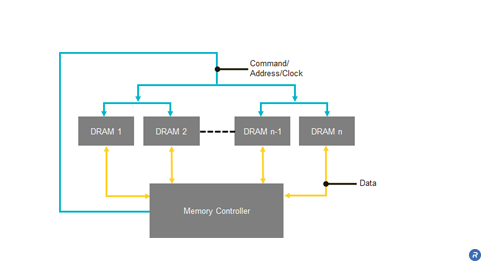
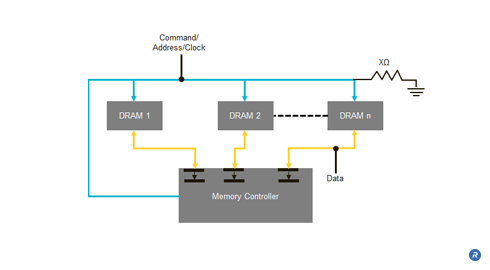
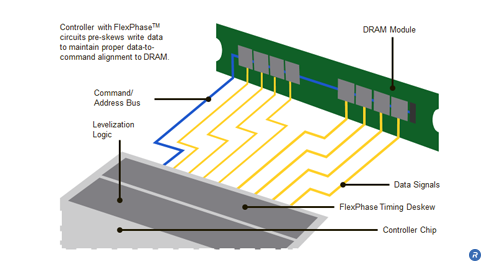
Fixtures that use traditional free-space reflectors — those that allow light to travel through air — can be cumbersome and inefficient when producing high-intensity beams of light. As an alternative to free-space reflectors, SolidCore™ reflectors are compact optics that produce high-brightness, collimated beams ideal for high-powered spotlights. SolidCore™ Reflectors enable smaller, thinner and lighter-weight fixtures that can be white or multi-colored by combining reflectors using red, green and blue LEDs.
- High-efficiency, molded reflectors
- Up to 75% reduction in reflector size for equivalent beam angle
- Produces tightly controlled, high-intensity beams ideal for spotlights
- Adjustable light emission according to the radius of the optic
What are SolidCore™ Reflectors?
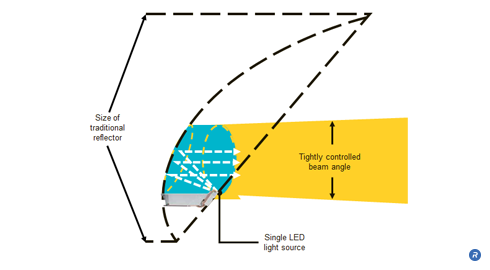
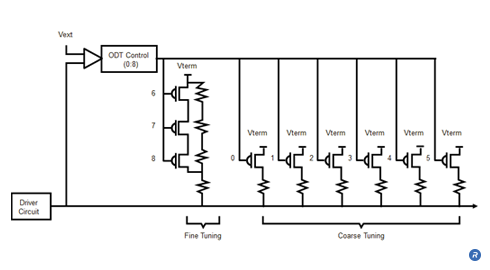
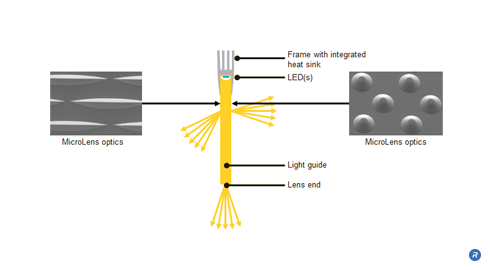
SolidCore™ Reflectors take advantage of the higher refractive index of plastic versus free space to produce a tighter angle of reflection. They are made of molded plastic, and unlike free space reflectors produce less variation in magnification and are far more compact. Each SolidCore reflector uses a single, high power LED. Light is directed to the reflective surface using a customized light pipe. The angle of the high-intensity, concentrated beam emitted by the SolidCore reflectors is determined by the radius of the optic. For example, beam output angles as tight as 3 degrees can be achieved with a 4″ radius optic.
Who Benefits?
With SolidCore reflectors, lighting designers are able to effects with much greater control, precision and intensity than ever before while maintaining power efficiency. The ability to control the beam angle and achieve color mixing delivers a richer and safer experience to consumers in multiple applications including entertainment, architecture, and outdoor lighting.